
はじめに
いつも固い話題ばかりブログに書いておりますので、今日は柔らかめの話題を取り上げます。先日、私の友人が「小江戸大江戸200km」というウルトラマラソン大会に参加しました。
最大36時間かけて206kmを踏破するという過酷なイベントです。
そのイベントに参加した友人の記録ですが以下の通りにWebサイトに掲載されています。
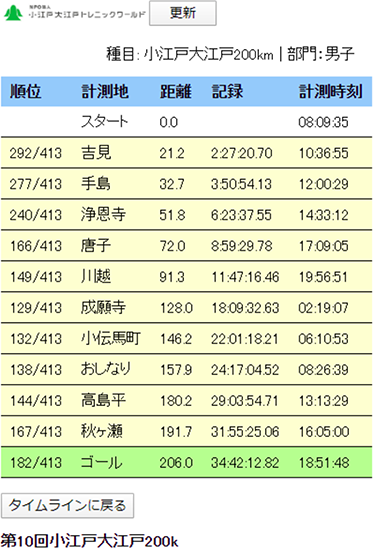
5列からなる上記データの列構成は以下の通りになっています。
- 順位
- 計測地名
- スタート地点から計測地ごとの累計距離
- スタート地点から計測地ごとの走行時間
- 計測した時刻
このデータをデータベース(今回はBigQuery)にアップロードして、SQLでデータプレパレーションを行い、BIツールTableau側ではあえて計算式を利用せずに、計測地間ごとの平均速度を可視化してみたいと思います。
SQLが使えるよう、まずはBigQueryにアップロードする
SQLはデータベースに対して適用するので、まずはデータをBigQueryにアップデートする必要があります。BigQueryのカラム名(=列名)には、日本語などの2バイト文字は使えないので、大会のデータをCSVに落とし、手元のCSVファイルでカラム名を英数に変更します。
するとBigQueryにアップデートできるようになります。
こちらがアップロードが完了したテーブルのスキーマです。
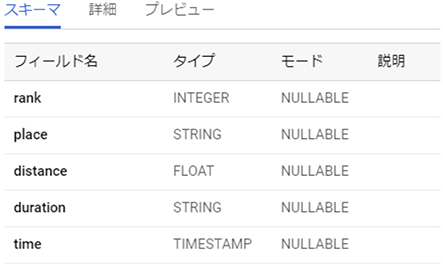
データベース上の「表」のことはテーブルと呼びます。スキーマとはどのような種類のデータをどのような構造で格納しているかを定義したもので、以下のスキーマからは各列の値がどのようなデータ型で格納されているのかを理解することができます。
具体的には、
- rankというフィールド名の列には、整数(INTEGER)型の値
- placeというフィールド名の列には、文字列(STRING)型の値
- disatnceというフィールド名の列には、浮動小数点型(FLOAT)型の値
- durationというフィールド名の列には、文字列(STRING)型の値
- timeというフィールド名の列には、タイムスタンプ(TIMESTAMP)型の値
がそれぞれ格納されていることが分かります。
データ型は、関数を使うときに少し気にする必要があります。いくら数字に見えてもデータ型が仮に文字列型であれば四則演算はできません。
プレビューボタンをクリックすると実際にどのような形でデータが格納されているのかを確認することができます。
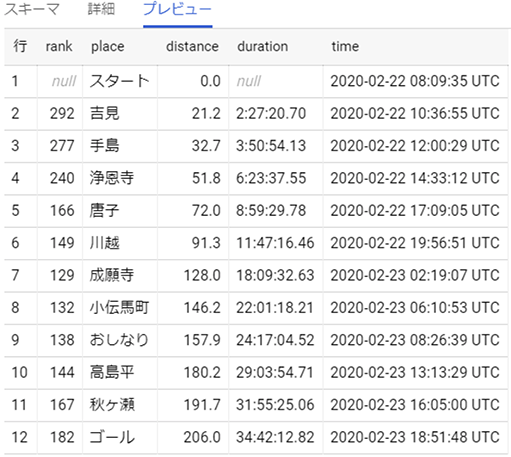
きれいにデータが格納されていますね。
SQLで直前の行の値を取得する
区間ごとの平均速度(分/km)を求めるには区間ごとの「所要時間」と「走行距離」が必要です。それらが同一の行にあれば、単純な割り算で平均速度は求めることができます。
ところが、上記のテーブルを見ると、所要時間はスタートからの累計の経過時間(duration)、もしくは計測時刻(time)が記録されていて、必要な所要時間はどの列にも存在しません。走行距離も同様で、スタートから累計の走行距離はdistance列に記録されていますが、区間ごとの走行距離は記録されていません。
さて、どうしましょうか?
ここで知ってほしいのは、SQLでは、同一行にある値同士は計算できる。ということです。ということは、例えば、計測地間の走行距離を求めるのに、上記のテーブルの各行に「直前行のdistance」があれば、引き算で区間における走行距離が求められそうです。
こんな感じですね。offset_distanceという新しい列に直前の行のdistanceの値が格納されているのが確認できます。
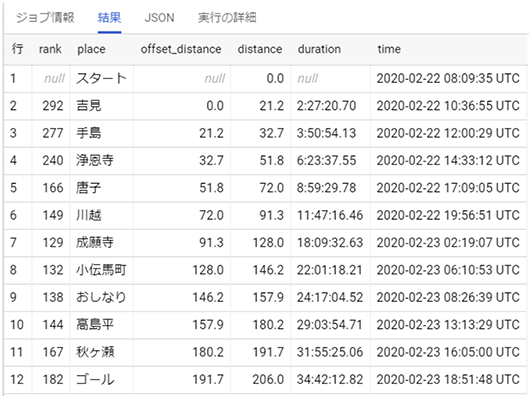
プレビューで見たもともとのテーブルに対して記述したSQLは以下のたった7行です。しかも関数を使っているのは3行目だけです。LAGという関数が(何行前でも良いのですが、何も指定しないと直前の行)直前の行のdistanceの値を取得しています。

こんな簡単な記述でデータプレパレーションができる。ということをまず感じていただければ嬉しいです。
では、distanceからoffset_distanceを差し引いて、区間の走行距離を求めます。
rankは今は 不要なので、取得しないことにして、4行目を追加して、以下のように記述しました。

結果は、以下です。step_distanceの列を見てください。うまくいっていますね。
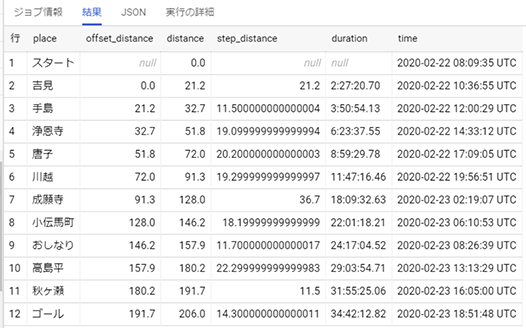
SQLでタイムスタンプ型の値の引き算をする
step_distanceで区間間の走行距離が取得できたので、次は、区間間の所要時間を取得します。 考え方は走行距離の場合 と同じで、直前の行のtimeの値を取得して、例えば
offset_timeとし、timeからoffset_timeを引き算すればいいですね。
SQLは以下の通りになります。不要な列は除いています。

結果 は以下の通りです。5行目にあるTIMESTAMP_DIFFというのがタイムスタンプ型の値の引き算をする関数です。最後の引数、minuteを指定しているので結果 を分単位で取り出しています。
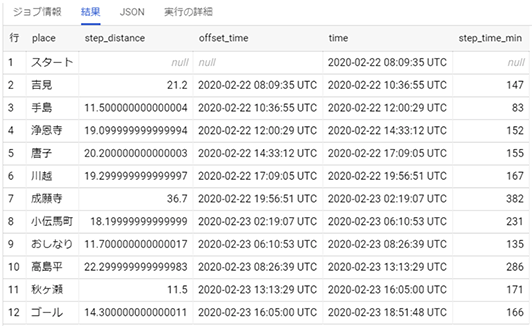
ここまでくれば、step_time_minを、step_distanceで割って、平均速度(分/km)を求めるのは簡単ですね。
SQLで見やすく整形する
以下のような結果を得ることができました。
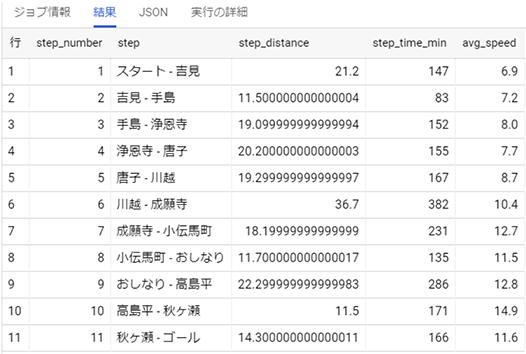
すっきりと見やすいテーブルになっていますね。上記を実現したSQLは以下となっていて、ROW_NUMBER()という行番後 を振る分析関数やCONCATという文字列連結 を行う関数を利用したり、サブクエリというテクニックで見やすく整形したりしています。

データプレパレーションしたデータにTableauから接続する
上記でデータプレパレーションの終わ った 状態 のデータはBigQueryにビューやテーブルとして保存することもできますし、TableauからBigQueryにカスタムSQLを使って接続することもできます。
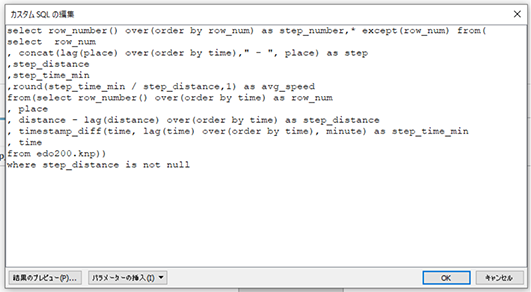
今回はBigQueryに記 述したSQLをそのままコピペ で利用して、カスタムSQL経由で接続してみます。
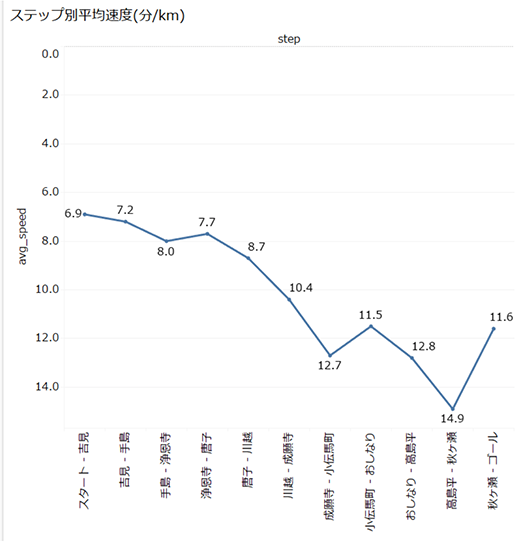
完成したVizはこちらです。データソースにavg_speedがあるので、Tableau側では一切計算式を作ることなく、可視化に成功しました。
SQLの分析関数(WINDOW関数)
上記の分析を行う上で、「肝」となった、直前の行の値を取得する関数はLAG()という関数でした。LAG()は分析関数(WINDOW関数とも呼ばれます)のひとつであるナビゲーション関数の一種です。分析関数には他にも、 番号付け関数や集計分析関数など、多くの強力な関数が用意され、必要なデータプレパレーションを助けてくれます。
まとめ
如何でしたでしょうか?SQLが特に、分析関数を利用してデータプレパレーションにどう使えるのか?おおよそのイメージはつかんでいただけたのではないでしょうか?
今後、データは、大きく、粒度が 細かく、また、複数のデータの結合 が必要になってくると思 われます。すると、我々 分析から価値を引き出すことを仕事にしている人間は、もうエクセルだけでは太刀打ちできないばかりか、BIツール「だけ」ができても効率良い可視化を実現することは難しく、SQLを駆使したデータプレパレーションのスキルが求められるようになるのではないかと思います。







