
今まで、SEOに関して以下のような意見を見聞きしてきたと思う。
- 1「新しいランキング要因が多すぎる!」
- 2「コンテンツの品質がすべてだ!」
- 3「ユーザーエンゲージメントが新しい王様だ!」
- 4「ソーシャルメディアシグナルがすごい!」
- 5「RankBrainがすべてのランキングを支配してしまった!」
お願いだから、私のナンセンスな投稿を大目に見て欲しい。今日の投稿ではランキング要因としてのリンクについて、新しいデータを共有するつもりだ。このレポートを読めば、リンクが今なおランキングにおいて重要な役割を担っていることが分かるだろう。ランキング要因としてのリンクの重要性が低下した、という話がひどく誇張さていることを示すデータも共有するつもりだ。事実、リンクは驚くほど強力なままなのだ。では、内容を掘り下げてみよう。
トップランキング要因に関するGoogle社員の最近のコメント
2016年3月23日、私は(Rand Fishkin氏、Ammon Johns氏と共に)Googleダブリン社のAndrey Lippatsev氏とのハングアウトに参加した。以下が重要な会話の一部だ。
Ammon Johns氏:RankBrainは今、検索結果に貢献する3番目に重要なシグナルと聞きました。最初の二つを知ることにも意味がありますか?
Andrey Lippatsev氏:ええ、もちろん。それが何か教えましょう。それはコンテンツとサイトへの被リンクです。
今さらそれを言う?
MozとSearchmetricsの研究が示唆するのは?
MozとSearchmetricsの両社が、ランキング要因について画期的な研究を実施した。そこにはリンクについての研究も含まれている。
下図で基本のデータをいくつか確認できる。
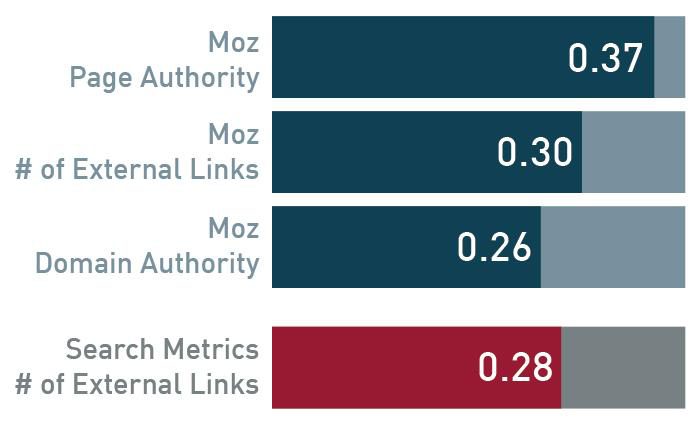
Moz Page Authority
Moz ページオーソリティ
Moz # of External Links
Moz外部リンク数
Moz Domain Authority
Mozドメインオーソリティ
Search Metrics # of External Links
Search Metrics 外部リンク数
上記のグラフはそれぞれの「検索順位を決める要因」と「実際の掲載順位が高いこと」の相関レベルを示している。
MozとSearchmetricsの研究ではどちらもリンク数の相関が比較的高かったが、他に調べた要因と比較して有意に高いわけではなかった。Google社員が重要なランキング要因の上位二つに入ると認めるほどにリンクが重要なのであれば、なぜその相関はもっと高い数値を示さなかったのだろうか?
その謎を解くための鍵は、MozとSearchmetricsの研究の評価方法を理解することにある。
両社とも個別にSERPの評価を行ってから、すべての結果の平均値を取っている。
(私はこれを「個々の相関の平均」アプローチと呼ぶことにする。)
また、両社の研究は商用検索用語にだけ焦点を当てている。
両社のアプローチに妥当性はあるものの、当社Stone Temple Consultingで培ったランキングにおけるリンクパワーの経験も鑑みて、私たちはリンクパワーにもっと焦点を当てて調べてみることにした。そして、リンクパワーの影響がよりあらわになる、いくつかの新しいアプローチをとってみた。
何を言っているのかというと…
つまり、「個々の相関の平均」のアプローチだけでは、検索アルゴリズムの全体像を提供しきれていないと思うのだ。
当社の研究結果
二人の専門家(Paul Berger氏とPer Enge氏)との協議にもとづき、私は二次平均にもとづく違う種類の計算を行った。その理由は、相関変数の二乗(相関値がRの場合、二次平均でR二乗を使う)を活用するためだ。
実際のところ、R二乗値は統計で意味を持つ。たとえば、Rが0.8であれば、R二乗値は0.64となり、Y軸の変動の約64%がX軸により説明される。Paul Berger氏が私に説明したように、R相関値を伴う意味のある文章はないが、R二乗値を用いれば相関関係で言いたいことに意味を与えることができる。
以下、この計算プロセスを視覚的に説明しよう。

Quadratic Mean Calculation
二次平均計算
Position
掲載順位
Total Links
リンク総数
(n=the # of SERPs tested)
(n= テストしたSERP数)
Take the Quadratic Mean of All Correlations
1.すべての相関の二次平均を取る
i.e.
2.つまり
異なる計算アプローチに加えて、私は別のクエリタイプも混ぜてみた。商用ヘッド用語、商用ロングテール用語、それから情報クエリもテストした。実際、当社のクエリの三分の二は情報クエリだった。それが、前述の実験と多少異なる結果を示した理由の一つかもしれない。

Links Per Ranking URL
ランキングURL毎のリンク
Domain Authority
ドメインオーソリティ
Page Authority
ページオーソリティ
当社の総リンクの相関結果は、ランキング要因としてのドメインオーソリティ(DA)とページオーソリティ(PA)の相関スコアより高かった。私はMozのRand Fishkin氏にその理由についてコメントを求め、以下の回答を頂いた。
当社ではPA/DAアルゴリズムを生成するために、異なるより広範なキーワードのコーパスを使用している。そのため、別タイプのキーワードクエリでは、異なるレベルの相関が示されるのは理解できる。非常に興味深いのは、raw linkの数が、特定のコーパスではより良い結果になる傾向があるということだ。私は、様々な評価基準が任意の一連のキーワードにどう相関するのかを、いつかMozが示すことができればと思う。(たとえば、あなたがランクを追跡している何千ものキーワードの相関関係が確認できれば、これほど素晴らしいことはないと思わないか?)
もう一つ着目したいのは、当社の総リンクスコアの相関がMozやSearchmetricsに比べて高いということだ。上記に示したスコアは別の方法論を取っているが、両社と全く同じ方法論(「個々の相関の平均」アプローチ)を採用したとしても、より高い結果を得ることになる。
以下に、「個々の相関の平均」アプローチを使った当社のリンクスコア計算の直接的な比較を示す。
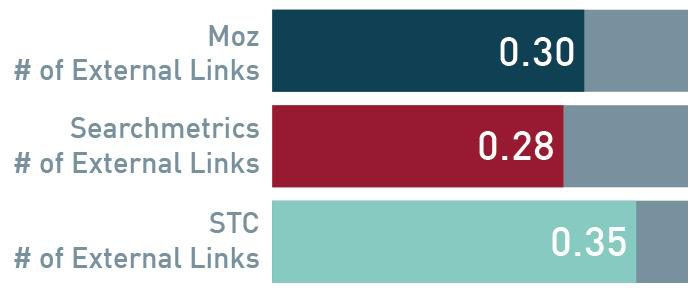
Moz # of External Links
Mozの外部リンク数
Serachmetircs # of External Links
Serachmetircsの外部リンク数
STC # of External Links
StoneTempleConsultingの外部リンク数
この場を借りて、感謝の意を表したい。当社の全データはMoz APIを使って取得したもので、Mozチームにはこの研究のあらゆる面でサポートして頂いた。
ランキング要因としてのリンクの集約的評価
私は個々の相関の平均と二次平均のどちらのアプローチも非常に有効であると考えるが、両者の限界の一つは、高い負の相関を伴うごく少数の結果値が、全体的なスコアを著しく低下させてしまう可能性があるということだ。
そのため、私は分析にいくつか別のアプローチも図ることにした。まず一つ目は、より集約的な方法でリンクを測定することだ。これによりリンクの量を正常化した。それから、ランキングポジションにもとづいて、すべての検索結果の合計を取った。計算式は以下のようになる。

Total Links By SERP Position Calculation
SERPポジションによるリンク総数の計算
1.Normalize total links for each SERP so highest “link total”=1
SERPごとに最高の“リンク合計数”=1とし、リンク総数を正常化する。
2.Sum Total links by position
ポジションによるリンク総数を合計する
Post 1 Total
ポジション1の合計
links to Position 1
ポジション1へのリンク
Post 2 Total
ポジション2の合計
links to Position 2
ポジション2へのリンク
Post 50 Total
ポジション50の合計
links to Position 50
ポジション50へのリンク
3.Calculate Spearman & Pearson Correlations on the Resulting Array
結果の配列で、スピアマン及びピアソン相関係数を使って計算する
Total links
リンク総数
Normalized links
正常化されたリンク
i = SERP #
i = SERP 数
これをする価値は、違った方法で負の相関の影響を取り除けるためだ。このように相関を見ると、以下のことが分かる。

Pearson Correlation
ピアソン相関
Spearman Correlation
スピアマン相関
私はまた、この相関を以下のように見直してみた。引き続き正常化されたリンクの合計を使うのだが、10位ずつをひとまとめにグループ化した。
つまり、トップ10の正常化されたリンクの合計を加算し、同様にランキングポジションが11〜20位、21〜30位といった具合に加算していった。それから、各10のポジションブロックにランクする内容を確認するために相関を計算した。その結果は以下のとおりだ。

Total Links by Block of 10 SERPs Calculation
SERP10づつに分けた各ブロックのリンク総数の計算
Similar to Model 2 – We still Normalize the Data
モデル2に類似 – データを正常化している
All the Links
すべてのリンク
Where i = the ranking position
i = ランキングポジション
2. Take the Pearson / Spearman for these 5 data points
2. ピアソン/スピアマン相関を5つのデータポイントに使用
上記の計算では、単にすべてのランキングポジションをSERPポジションに集約するよりもう少し粒度の細かいアプローチを取ることができ、かつ「個々の相関の平均」手法の制限をいくつか排除することが出来る。結果は以下のとおり。

Aggregate Correlations Across Blocs of 10 SERPs
SERP10のブロックでの集約的相関
Pearson Correlation: 0.77
ピアソン相関: 0.77
Spearman Correlation:1
スピアマン相関: 1
相関は0.39からほぼ完全に違った値を得る結果になったが、これらの数値が示唆するものは何なのだろうか?
私が考えるに、集約的なアプローチは“平均”に基づいた計算が示すものより、リンクがはるかに重要なファクターであることを示している。
Digging Into What’s Going On Here
何が起こっているのか掘り下げてみる
この分析をサポートする方法として、 検索結果でリンクの影響を受けそうにないものの割合やその内容を把握するために、数百件を手動で分析してみた。それはどんなタイプの結果なのか?
- 1.ローカルな結果(地図の結果ではなく、局所的に影響のある結果)
- 2.多様性を優先した検索(QDD)
- 3.特集記事
当社の分析では、検索結果の約6%は上記のタイプの結果であるということがわかった。しかし、あくまでそれは一つの要因にすぎず、“平均”にもとづく計算と集約的な計算の違いを説明するものではない。
しかしながら、もっと大事な問題はコンテンツの品質の役割を理解することだ。Googleはコンテンツとリンクが最も重要なランキング要因だと言った。そのため、“リンクスコア”と“コンテンツスコア”を単純に乗算する非常に簡略化した方程式を想像するのは難くない。
ではここで、完全に仮定上の議論だが、コンテンツスコアがおそらくリンクスコアより価値があると主張してみたいと思う。結局、コンテンツに関連性がなければ、上位表示されるべきではない。それは理にかなっている。さらに、コンテンツの一部の関連性のレベルは非常に変わりやすい。
以下はその影響をかなり単純化したものだ。
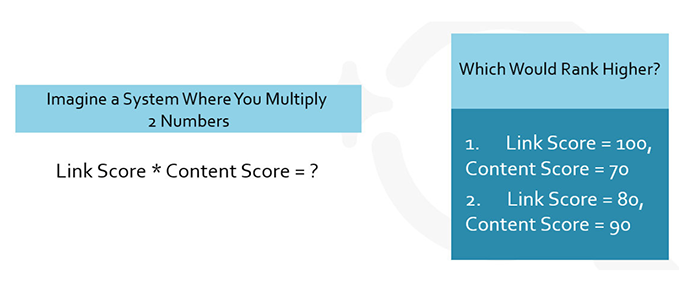
Imagine a System Where You Multiply 2 Numbers
2つの数字を乗算するシステムを想像してください
Link Score * Content Score = ?
リンクスコアxコンテンツスコア=?
Which would rank higher?
どちらのランクが高い?
Link Score = 100, Content Score = 70
1.リンクスコア=100、コンテンツスコア=70
Link Score = 80, Content Score = 90
2.リンクスコア=80、コンテンツスコア=90
上記の図では、“リンクスコア”が著しく低くても、シナリオ2の方が実際のところ、掲載順位が高くなる。
リンクスコアが1から100で示され、コンテンツ関連のスコアリング要因(関連性及び品質)が指数関数的に減衰すると想像すれば(品質と関連性におけるわずかな変化が“コンテンツスコア”に大きな影響を与える方式)、リンクは低い関連性または弱いコンテンツを完全に克服することはできないだろう。
コンテンツに関連性や競争力がない場合、リンクはランキングの助けにならない。もしそれらがある場合、リンクは違いを生むだろう。
重要なポイント:上記の議論はコンテンツスコアリングの重要性とランキングアルゴリズムへのその影響の基本的なポイントを示す意図で行われた。これは私が確認したデータの分析と、次の項で示すケーススタディにもとづく私個人の意見である。
ケーススタディを使ってポイントを確かなものにする
当社のクライアントの多くがフォーチュン500企業であり、当社では彼らとともにハイエンドなコンテンツマーケティングのキャンペーンを行う。多数のクライアントを網羅した結果のサンプリングを以下に示す。
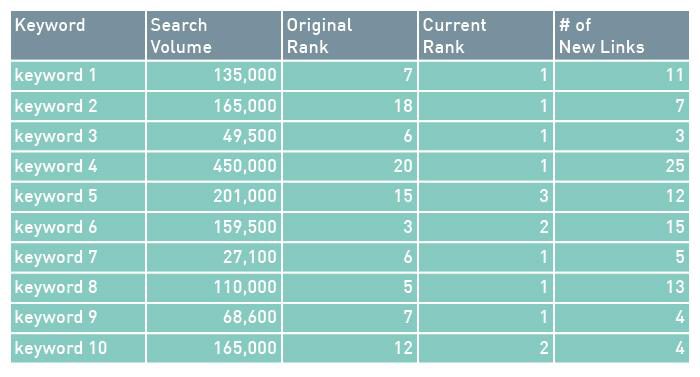
Keyword
キーワード
Search Volume
検索ボリューム
Original Rank
最初のランク
Current Rank
現在のランク
# of New Links
新しいリンク数
上記に示したサンプルの結果は当社で何百回も繰り返されたものである。しかし、低品質のコンテンツや、低い関連性のコンテツをランクさせるリンクは見つけられない。また、当社では非常に高い権威サイトからの認知を得ること、またはそこでコンテンツを公開できる事に焦点を当てて企業努力を続けている。当社のデータは高容量、低品質なリンクビルディングに基づいていない。
要約
Googleのアルゴリズムは進化し続け、オーガニック検索のトラフィック全体に影響を与えている多くの要因を目にしている。
最大の原因は以下のとおりだ。
- 1.有料検索に割れ当てられたより多くのスペース
- 2.画像検索やYouTubeなどの外部ソースからのより多くのコンテンツや、上記で述べたような別の要因
- 3.10未満のウェブ結果しかないページ
- 4.ローカルなウェブ、多様性を優先した検索(QDD)、特集記事の結果など、明らかにリンク主導ではないウェブ結果の割合
その結果、リンク以外の要因に駆動されてSERPの最初のページに表示される結果は10未満である。それは、そのページのランキングにリンクが全く関与していないという意味ではなく、関与の割合が少ないということだ。
一方で、当社のデータを見ると、リンクはランキングで主要な役割を果たし続けていることを示唆している。
さらに、当社のケーススタディのデータが以下のシンプルな結論を示した。
ページの関連性や品質の問題に直面していなければ、リンクはランキングに大きな影響を与えることができるし、与え続ける。
研究は、関連性や品質の問題が少ないほど、リンクがまだ非常に強力なランキング要因であることを示している。
注意:当社のデータはリンク数にもとづいた相関を示すことに焦点を当てているが、それはリンクの品質が関係ないという意味ではない。もちろん当然関係がある。
そして(強調しておきたいのだが)、リンクの購入は考えない方がよい。
では、本当の結論はなんなのだろうか。
- 1.素晴らしいコンテンツとユーザーエクスペリエンスを構築すること。現代のデジタルマーケティングの世界では、(ポーカーの)掛け金のようなものである。
- 2.積極的にビジネスを販売し、人々が貴社について執筆したり、リンクを貼りたくなるようなことをする。
この2つを実行していくべきである。
コメント
今回は、Stone Temple Consluting社の記事から、リンクの最新調査に関する情報を翻訳させていただきました。
今回この記事を紹介させていただいた理由としては、「リンクがまだ重要なファクターである、ということを示すため」、というよりも、SEOのリサーチが上記のような統計的なアプローチを伴うものである、ということを示すため、になります。
今後は、このようなデータを用いた分析がマーケティングの諸分野においてより重要視されていくのではないでしょうか。
プリンシプルでは、あらゆるデータを可視化してマーケティングに役立てるお手伝いをさせていただいております。
マーケティングでのお悩みがございましたら、ぜひお気軽にご相談ください。







