
はじめに
「キャンペーンAはコンバージョン率3.3%、キャンペーンBはコンバージョン率5%ですから、キャンペーンBに予算を増やしてもっとキャンペーンBからのトラフィックを増加させましょう」
このアドバイスは果たして”正しい”でしょうか
このブログの読者の7、8割の方は「正しい」と言ってくれる気がします。
1割の方は、「正しくない」と言う気がします。そして、その理由は「キャンペーンBがブランドワードやリマーケティングだったら、今以上にトラフィックを増やすことは難しいから」など、実現性があるのか?を争点にするでしょう。もしくはキャンペーンAのCPCが100円でキャンペーンBのCPCが200円かもしれないから」という、ROIの観点が考慮されていないからと言うかもしれません。
そして残りの1、2割の人が(暗黙のうちにかかる費用は同一という前提を置いたうえで)「分からない」と答えてくれるでしょう。そして、その理由は「統計的に有意かどうか検定されてないから」と答えてくれるでしょう。
Web解析に統計学的なアプローチがあまり広がっていない理由
「統計的に有意?」このブログの読者の方は、あまり耳にしたことがない、もしくは、概念はわかっているが、Web解析においては聞いたことがない方が多いのではないかと思います。
総じて、Web解析にはこれまであまり「検定」や「推定」などの統計学的考え方が入ってこなかった気がしています。そしてその理由は以下の3点ではないかと思います。
- 手にしているデータが「標本=サンプル」だという意識がなかった
- (一般的に)サンプルサイズが大きく、統計的検定を行ったとしても、P値が十分に小さくなるケースが多かった
- Google アナリティクスに統計的確認を行う要素が不足しているので、ユーザーが啓蒙されるチャンスがなかった
以下、上記の3点について補足的な説明をします。
「サンプル」という概念の不足
統計的仮説検定や推定には、「母集団」と「サンプル」の考え方が前提としてあります。母集団全体を測定することができない、もしくは現実的でないので、そのうちの一部をサンプルとして取得して測定し、観測された値から母集団の性質を推定し、また、母集団に対する仮定の正しさを検定するという考え方です。
一方、Google アナリティクスに表示される各種の指標については、一般にはそれがサイト訪問を行ったユーザーの全数であり、母集団だ。という考えが暗黙のうちに存在していると思います。
しかし、よく考えてみると、「(仮に日本をターゲット市場としているとすると)日本にいる人全員」が母集団であり、たまたま自社サイトに訪問してくれてGoogle アナリティクスにデータを残してくれた方は「サンプル」である。という考え方の方が現実に即していることが分かります。Google アナリティクスで取得したサンプルから母集団の性質を判断し、まだ見ぬ母集団に対してのアプローチを変えましょう。というのがGoogle アナリティクスをツールとして利用するWeb解析の目的だからです。
統計的に有意になりやすいサンプルサイズが得られることが多い
統計的検定においては、サンプルサイズ(サンプルの個数)が大きいと、統計的に有意な差があるかどうかの判定に利用される”P値”と呼ばれる値が小さくなる傾向にあります。そしてP値が小さいと「統計的に有意な差がある」と判断されます。
P値について説明すると非常に長くなりますのでこのブログでは「ある計算によって求められたP値が0.05以下であれば統計的に有意だと言える」とだけお考え下さい。
例えば、冒頭の「キャンペーンAとBでのコンバージョン率に差があるか?」というお題に対し3.3%と5%という違いが同じであっても、P値はサンプルサイズが大きくなればなるほど、小さくなる性質があります。
以下の3つのケースでサンプルサイズ(この場合セッション)によるP値の違いを確認してください。※以下の表のP値は自由度1のカイ二乗検定によるものです。カイ二乗検定についてはExploratoryで行うカイ二乗検定の記事をご参照ください。
| ケース | キャンペーン | セッション | CV | コンバージョン率 | P値 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 |
|
|
|
|
0.148 |
| ケース | キャンペーン | セッション | CV | コンバージョン率 | P値 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2 |
|
|
|
|
0.076 |
| ケース | キャンペーン | セッション | CV | コンバージョン率 | P値 | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 3 |
|
|
|
|
0.041 |
Google アナリティクスの性質
Web解析を行うためのデファクトのツール、Google アナリティクスには統計的に確認を行うための要素はほとんど入っていません。
例えば、「平均ページ滞在時間」という指標があります。「平均」があるということは、以下の模式図のように、ページビューごとのページ滞在時間があり、それを合算してページビュー合計で割って計算しているのですが、平均値以外の記述統計量である、中央値、最頻値、分散、標準偏差などは提供されません。四分位範囲から計算される「外れ値」についても指摘されません。(ちなみに、以下のデータでページ滞在時間22秒は外れ値です。)
| ページビューID | ページ滞在時間(秒) |
|---|---|
| 1 | 5 |
| 2 | 12 |
| 3 | 22 |
| 4 | 6 |
| 5 | 2 |
| 6 | 3 |
| 7 | 4 |
| 8 | 5 |
| 9 | 6 |
| 10 | 8 |
| ページビュー計 | ページ滞在時間計 | 平均ページ滞在時間 |
|---|---|---|
| 10 | 73 | 7.3 |
そのため、Google アナリティクスユーザーに統計的な概念が根付きづらかったという事情があるものと思います。
Web解析に統計学的なアプローチは不要なのか?
仮に、現在の状況ではWeb解析に統計学的なアプローチがあまり入ってきていないとして、Web解析アナリストにそれは不要でしょうか?
自社やご自身の置かれた環境によって答えは変わってくると思いますので、絶対的な”正解”はないにしても、おそらく「統計学的なアプローチが必要になる場合があるので、不要とは言えない」、「自分のスキルの中に持っておいた方が良い」が、私なりの答えです。
理由は、以下の通りです。
- いつもサンプルサイズ十分に大きいことが担保されていない。
① 多ディメンション解析
② スピードを求められるABテスト - GAのような統計学的なアプローチに基づかない基づかないツールでは判断を間違えることがある(例:平均値が適切な代表値ではない)。
それぞれを見て行きましょう
多ディメンション解析
「キャンペーン別のコンバージョン率」に適用されている「●●別の」という分割軸(その分割軸のことをディメンションと呼びます)はたった一つです。ですが、「デバイスカテゴリ」や「曜日」、「時間」、「セッション数(何回目の訪問か?を整数で表すディメンション)」、「都道府県」などのディメンションを適用してコンバージョン率を比べたいことが出てきます。そのように多数のディメンションを適用して行う分析を多ディメンション解析と呼んでいますが、「モバイルデバイスの、土日の午後8時以降の新規ユーザーで、東京以外から発生したセッション」におけるキャンペーンAとBのコンバージョン率を比べる場合、サンプルであるセッションの数は減ります。つまりより小さなサンプルサイズでキャンペーンAとBを評価する必要が出てくるということです。
早期に結果を知りたいABテスト
ABテストにおいてよくあるシーンですが、早くA/Bテストの結果を判断し、より成果の高いキャンペーン、クリエイティブ、ランディングページを採用したい。そうした場合、通常、「早く」判断をすることが求められます。ABテストの成果の悪い方に触れたセッションが、本来得べかりしコンバージョン率を得られなかった機会損失になるためです。
その場合、比較的小さいサンプルサイズで判断せざるを得ない状況があるかもしれません。
平均値が代表値として適切でない
前述の通り、Google アナリティクスには統計学的な要素は含まれておらず、記述統計量について提供されるのは「平均値」だけです。平均値が代表値として適切であれば、平均値を元に判断すれば”正しい”判断ができるのですが、現実には平均値が代表値としては望ましくないケースがあります。
その場合には、「平均される前のデータを取得し」、「統計学的なアプローチで他の記述統計量の確認を行う」必要があります。
例えば、プリンシプルの12月のトップページの平均滞在時間は、48秒でした。
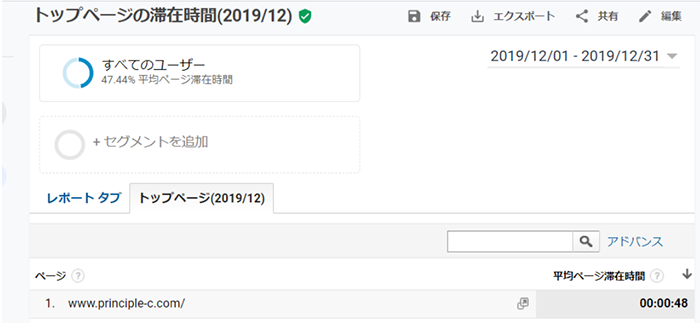
これしか情報がなければ、48秒を中心とした両側にすそが広がった釣り鐘状の分布を想像してしまいますが、実際には以下の通り、最頻値は6秒でした。
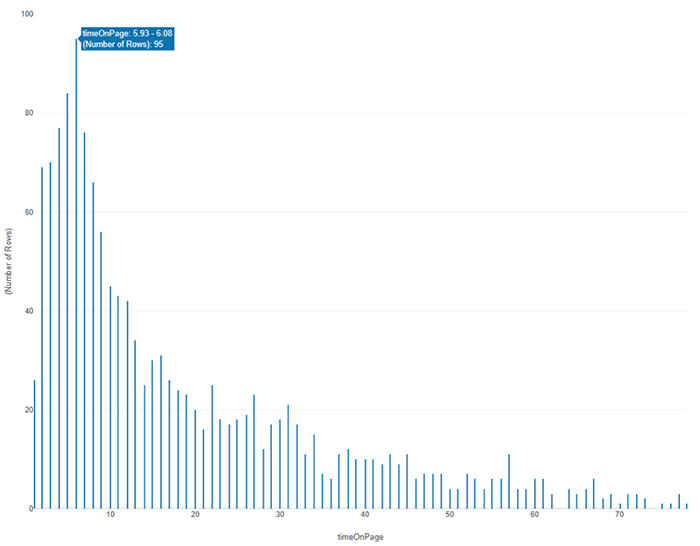
これほどまでに平均値と最頻値の違いがあり、かつ、この場合のように、代表値としてふさわしいのが最頻値である場合、平均に集計される前のデータを収取して統計学アプローチで「データが示す真の姿」に迫ることが必要になってきます。
まとめ
この記事のまとめです。
- Web解析にはこれまで統計学的なアプローチはあまり持ち込まれていなかった。
- その理由は、以下の3つであると思われる
① 母集団 vs サンプルという考え方の欠如
② サンプルサイズが大きいことが多い
③ GAに統計学的な要素が含まれていない - 一方、以下のようなケースもあるので、Web解析アナリストは「統計学的アプローチ」も身に着けたほうが望ましい。
① 多ディメンション解析ではサンプルサイズが十分大きくない場合がある
② ABテストでは、できるだけ早く、サンプルサイズが十分に大きくないタイミングで判断したい場合がある
③ 平均値が代表値として適切でない場合がある







