はじめに
先日、こちらのブログで、SQL、特に分析関数(ウィンドウ関数)がデータプレパレーションを行う上で、非常にパワフルだというお話をしました。しかし、データプレパレーションを必要とする人が全員SQLを自由自在に書けるという訳でもない。というのも事実だと思います。
では、そうしたSQLを書けない人は、従来通り、エンジニアに依頼し続けるしかないのでしょうか?
その問いへの一つの答えが、「ツールでデータプレパレーションを行う」というアプローチです。今日は、シリコンバレー発、かつ日本人が開発しているExploratoryというツールを紹介します。
シナリオはこちらの記事とまったく同じで「206kmのウルトラマラソンを走破した友人のステップごとの平均速度の可視化」です。
BigQuery上のデータ
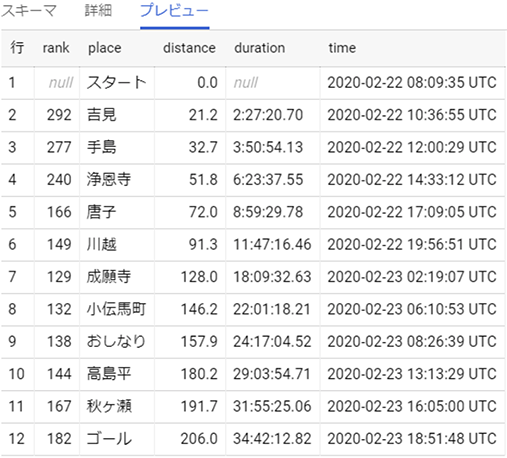
BigQuery上のテーブルはこちらです。
ExploratoryからBigQueryへのデータ接続
ExploratoryはエクセルやCSVなどのファイルや、Google アナリティクスやGoogleシートなどのアプリケーションに加え、データベースへの接続機能があり、以下のデータベースに対応しています。真ん中列の上から2つめにBigQueryもありますので、クリックし、ID/Passwordを入力の上、対象のテーブルを指定するとデータ接続は完了です。

データベースへの接続完了とサマリビュー
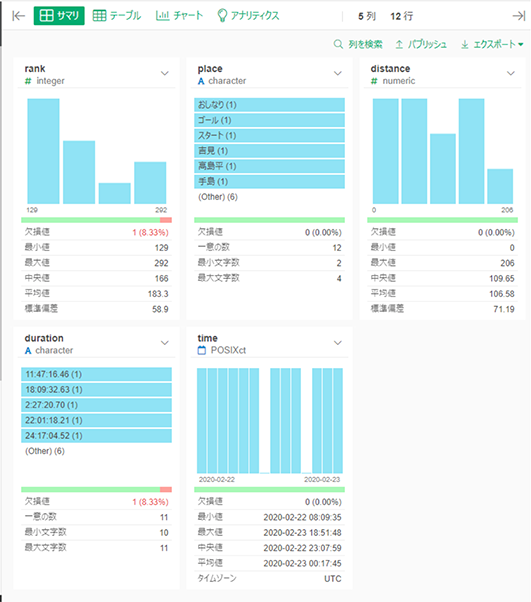
データベースに接続が完了するとデータが取得され、以下のような「サマリビュー」というビューが表示されます。
このビューは非常に優れており、全体のレコード数、一意な値の数(質的データの場合)、や基本統計量(量的データの場合)が一覧で確認できます。また、欠損値(NULLの数)なども明示されます。
データプレパレーションの開始
では、データプレパレーションを始めてみましょう。まずは、
- データを時系列順に並べ替え
- 直前行のdistanceを取得する
をやってみましょう。
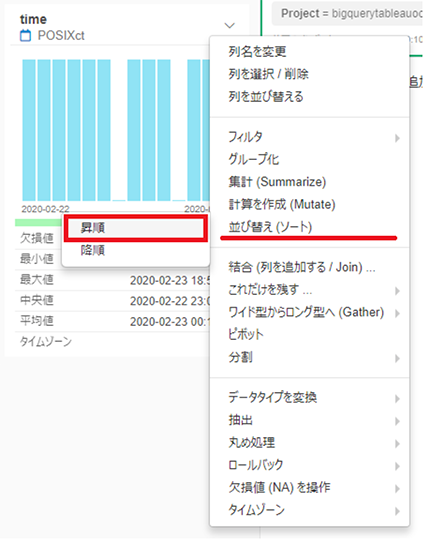
データを時系列順に並べるには、time列の下向き矢印をクリックし、「並べ替え(ソート)→ 昇順」をクリックします。
次に、直前行を取得するには、データラングリングのステップの「+」をクリックして計算を作成(Mutate)をクリックします。
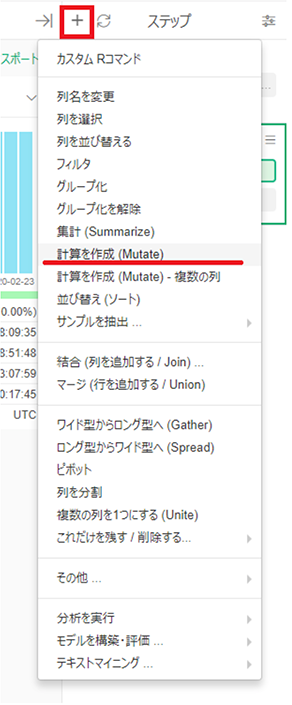
計算式で、lag_distanceを作ったところが以下の「計算を作成(Mutate)」ダイアログです。
SQLを書くよりはずいぶん簡単に直前行を取得できます。
テーブルビューでデータ全体を確認する
lag_distanceが意図した通りにデータに加わっているのか?を確認するには画面上部の「テーブル」をクリックし、テーブルビューを利用します。
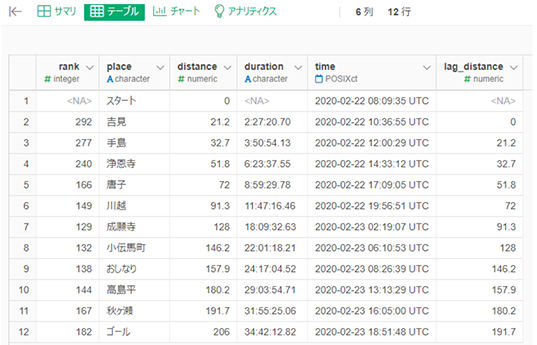
一番右に lag_distance列がありますが、きれいに「直前行のdistanceを取得しているのが分かります。
同様に直前のtimeを取得してlag_timeとの差を取る
同様に直前行のtimeを取得してlag_timeとした後、timeとの差をdurationという名前で作成しているのが以下となります。difftimeという関数を利用しています。この関数の名前は最初は分からないと思いますが、「関数一覧」のメニューから”time”などで検索すると見つかります。
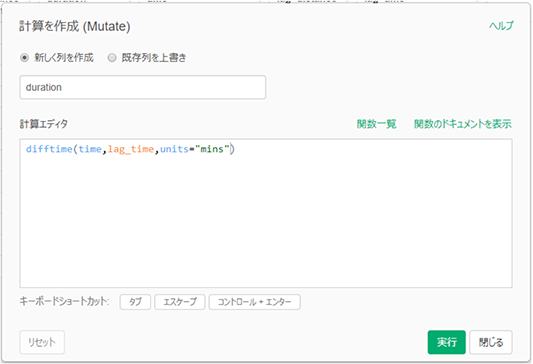
今一度、テーブルビューで確認してみましょう。同一の行に区間の距離を表す「step_sitance」、区間の走行時間(分)を表す「step_time」が格納されているのが分かると思います。
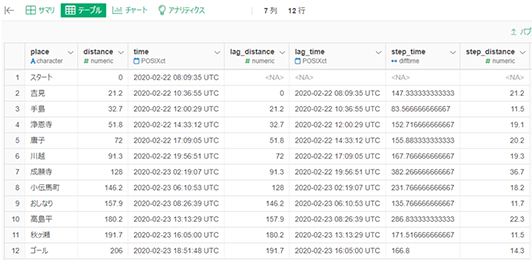
ステップの名前を分かりやすくする
各ステップを「吉見」ではなく、「スタート-吉見」のように区間の最初と区間の最後をハイフンでつないだ文字列にして分かりやすくします。pasteというのは文字列をつなぐ関数です。一行前のplace、ハイフン、当該列のplaceをつないでいます。
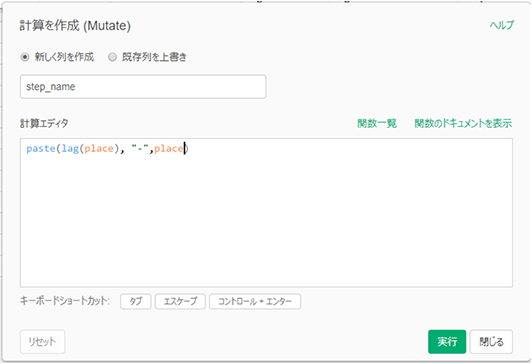
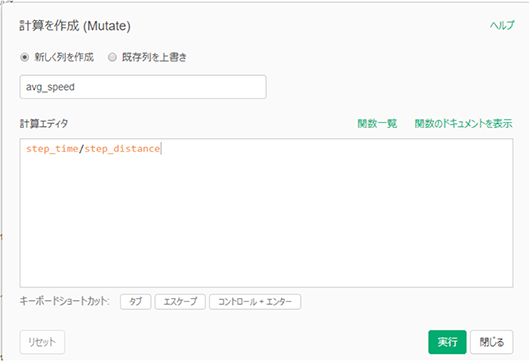
割り算の指標 avg_speedの作成
ここまで来たら簡単です。以下のMutateダイアログで、avg_speedを作成します。
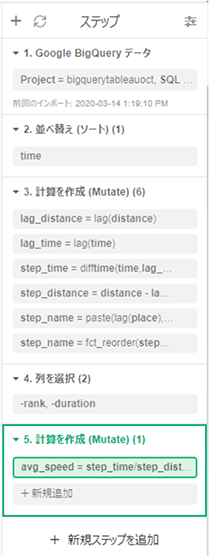
ラングリングステップの明示
このExploratoryの面白いところは、ここまでやってきた、
- データ接続
- timeの昇順での並べ替え
- 直前行の値を取得するしたり、列同士の引き算を行ったり、文字列加工を行う
- 不要な列を非表示にする
- 割り算の指標を作成する
などが、「ステップ」として画面右側に明示されていることです。どのようなラングリングをどのような順番で実行されたのかが分かるとともに、もし、おかしなところに後から気が付いた場合でも、当該ステップに戻って修正するということが非常に容易にできます。
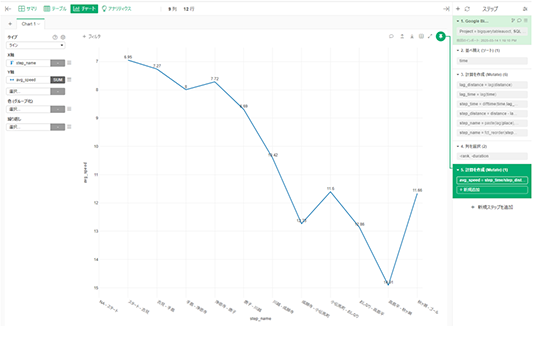
avg_speedの可視化
データラングリングが完了したので「チャートビュー」に遷移し、ラインチャートを選んで、X軸にstep_name、Y軸にavg_speedをプロットすると、こちらのラインチャートが完成します。
まとめ
いかがでしたでしょうか?SQLを全く記述することなく、データプレパレーション(=データラングリングと同義)が完了し、チャートまで完成しました。
Exploratoryはこのように、ラングリングだけでなく、可視化のケイパビリティも備えたツールです。しかし、実は、それだけではありません。
区間別のavg_speedが何に影響されて決まっているのかをdistance(累計距離)とstep_distance(区間の距離)で重回帰分析する。というような分析ケイパビリティも持っています。
以下がその結果です。
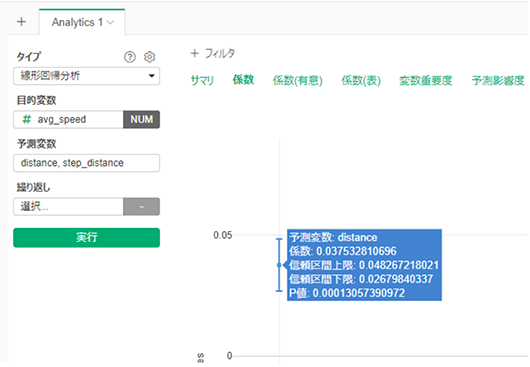
画面の一部を掲載していますが、avg_speedとdistanceが有意に相関しており、もし、step_distanceが一定であれば、distanceが1単位(この場合、1km)増えるごとにavg_speed(分/km)h、0.0375分/kmだけ増える(=遅くなる)ということが分析できました。
累計の距離が長くなるほど疲労が蓄積し、平均スピードが遅くなるであろうという我々の直感とも合致した結果となっています。
一方、以下の画面の通り、P値が0.05よりもかなり大きいためavg_speedとstep_distanceとは有意な相関関係がありませんでした。

SQLが書けない、学ぶ時間もない。という方は、このように強力なケイパビリティを持ったツールを使いこなすことで、業務上必要となる能力を身に着ける方法もあるかと思います。







