
この記事は、WEBやデータ分析に関する投稿をみんなでしてみよう Advent Calendar 2020の22日目の記事です。
多分、ブログを書くのも年内最後になります。何を書こうかなぁ?と考えたのですが、やはり自分的には今年は機械学習の年だったので、Exploratoryで締めたいと思います。
お題と解き方
お題は、このブログ記事のタイトルにもしました「サービス紹介ページはお問い合わせに効いているのか?」です。よく、お客様からもご質問を受けますね。
このお題への解の出し方はたくさんあると思うのですが、この記事では「ロジスティック回帰」を利用してみたいと思います。
データラングリング
Exploratoryでは分析の種類として「ロジスティック回帰」を選んで「実行」をポチっとするとあっという間に結果が出ます。ですので、その部分に掛かる労力は、右手の人差し指を1mm程度動かしてトラックボールの左ボタンを押すだけです。
が、手間がかかるのはデータラングリングと呼ばれるデータの整形です。そしてデータラングリングはExploratoryの得意技です。
今回ロジスティック回帰分析を動かす上で、必要となるデータの要件は以下です。
- 1行が1ユーザー(※)となっている
- サービスページを見たかどうか?というブール型のカラムがある
- お問い合わせをしたかどうか?というブール型のカラムがある
(※)「サービスページを見たユーザーがお問い合わせをしやすいのか?がお題の場合は1行が1ユーザーとしますが、もし、お題が「サービスページを見たセッションがお問い合わせに繋がりやすいのか?」であれば、1行を1セッションとします。このように、関心のあるものについて1行にするというのが機械学習を利用するときのデータラングリングの大原則ですので、覚えておくと良いかな。と思います。
こんな感じですね。
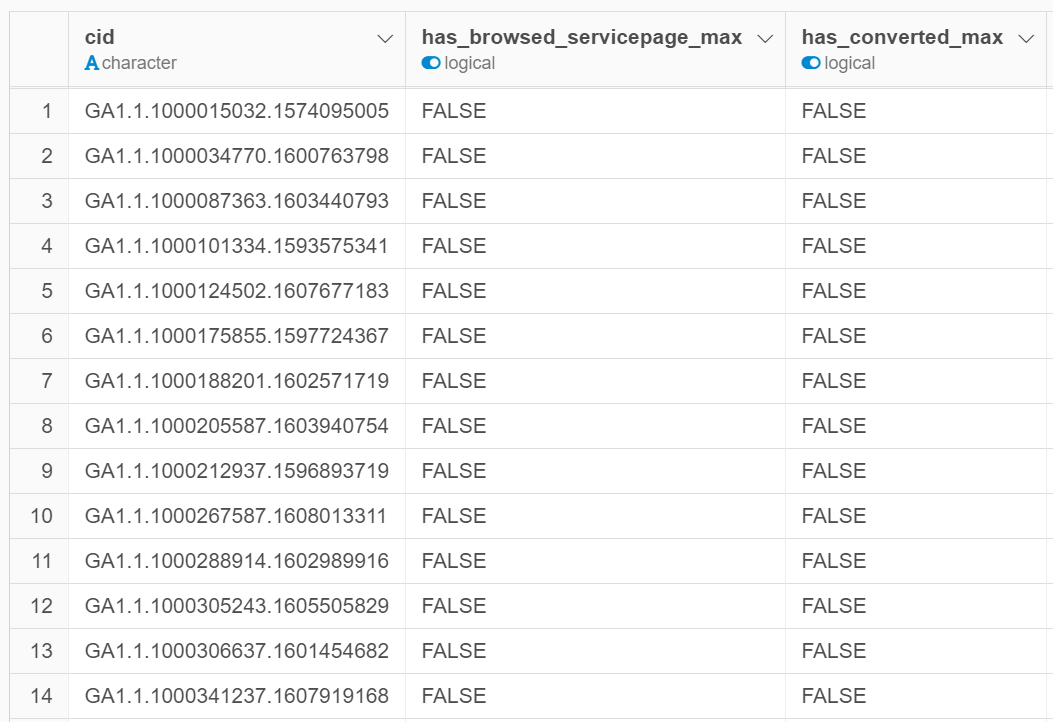
- cidはユーザーを一意に特定するID
- has_browsed_servicedpage_maxは、サービスページを見たかどうか?
- has_converted_maxは、お問い合わせをしたかどうか?
です。
肝となるラングリングのステップ
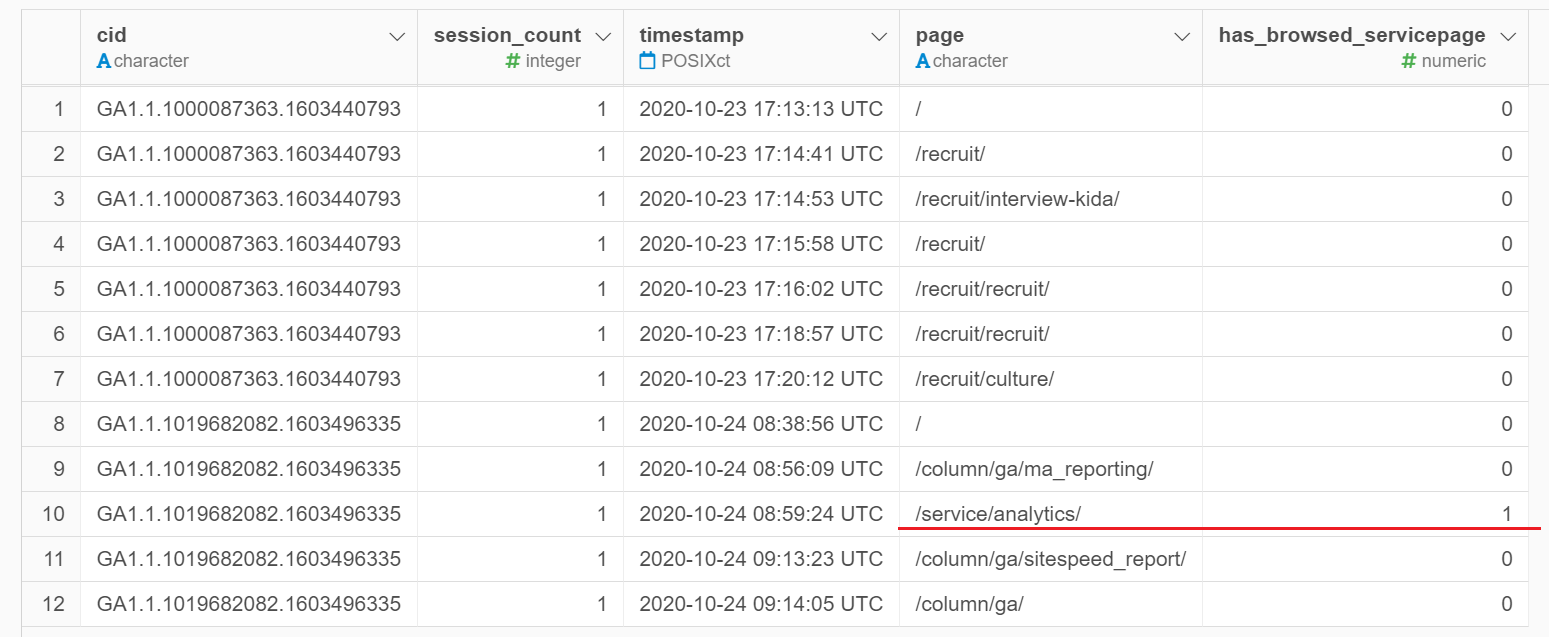
Googleアナリティクスから取得したデータは普通、最初はこのような形をしています。赤枠のユーザーさんは複数ページを見てくれていますが、このユーザーさんはサービスページを見ていないので、このユーザー1レコードにまとめると、「サービスページを閲覧したか?」の列は、FALSEとなるようにラングリングしなければなりません。ですよね?
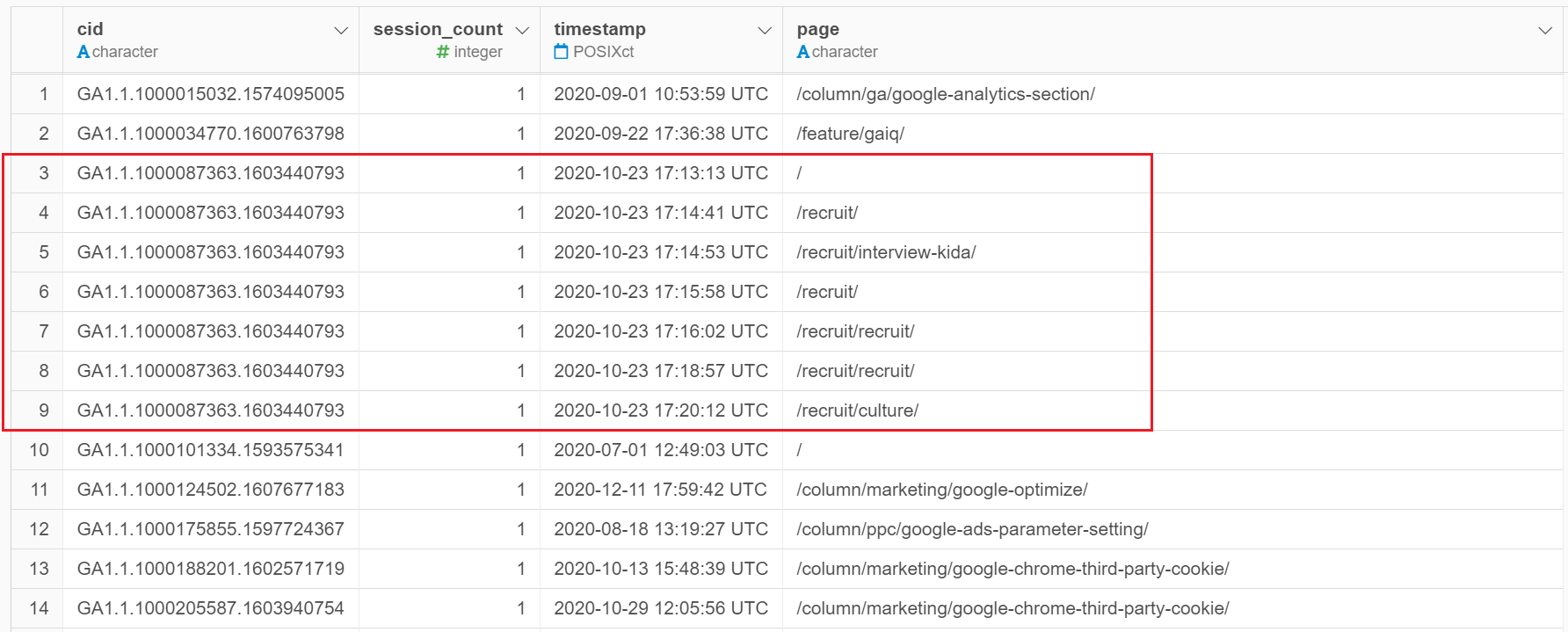
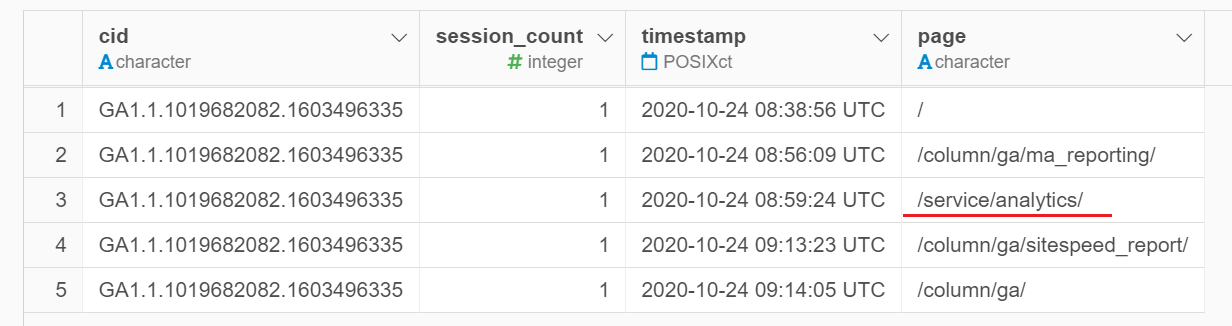
一方、こちらのユーザーさんは、「サービス紹介をページを閲覧したか?」の列はTRUEとなるようにしなければなりません。
そのラングリングを可能にするのは、以下の3ステップで行います。
第一ステップ = 行単位で「サービスページを閲覧したら1」のフラグを立てる
Exploratory内で以下の計算式を書きます。見慣れない読者の方もいらっしゃるかもしれませんが、やっていることは単純で、行単位で見ていったときに(どのユーザーかは全く問わず)pageが "/service/"で始まっていたら1を、そうでなければ0フラグとして立て、カラム名(これは任意の名前でOK)は、has_browsed_serivcepageとしなさい。という命令となっています。
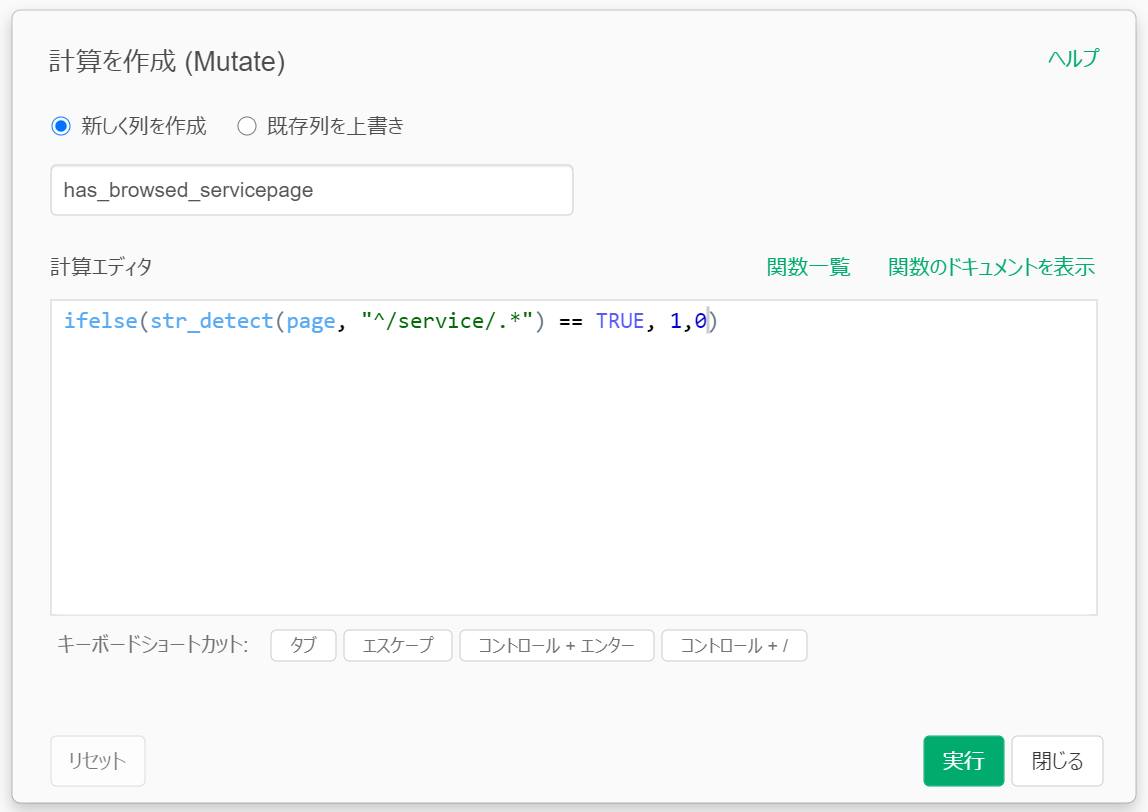
結果はこうなります。特に難しくないですね。
第二ステップ = ユーザー別にグループ化して最大値を取得する
メインとなるのがこのステップです。ユーザー別に1行にする作業はデータラングリングでは「グループ化」と呼びます。。
そして、このケースでは、グループ化したユーザーごとに、has_browsed_serivcepageの最大値を取得します。(合計値でもなんとかなりますが、最大値の方が第三ステップがスマートに行えますので、最大値を推奨します。)その作業を「集計」と呼びます。
Exploratoryでこの「グループ化」と「集計」を行うステップは「集計(Summarize)」です。実際の画面は以下となります。
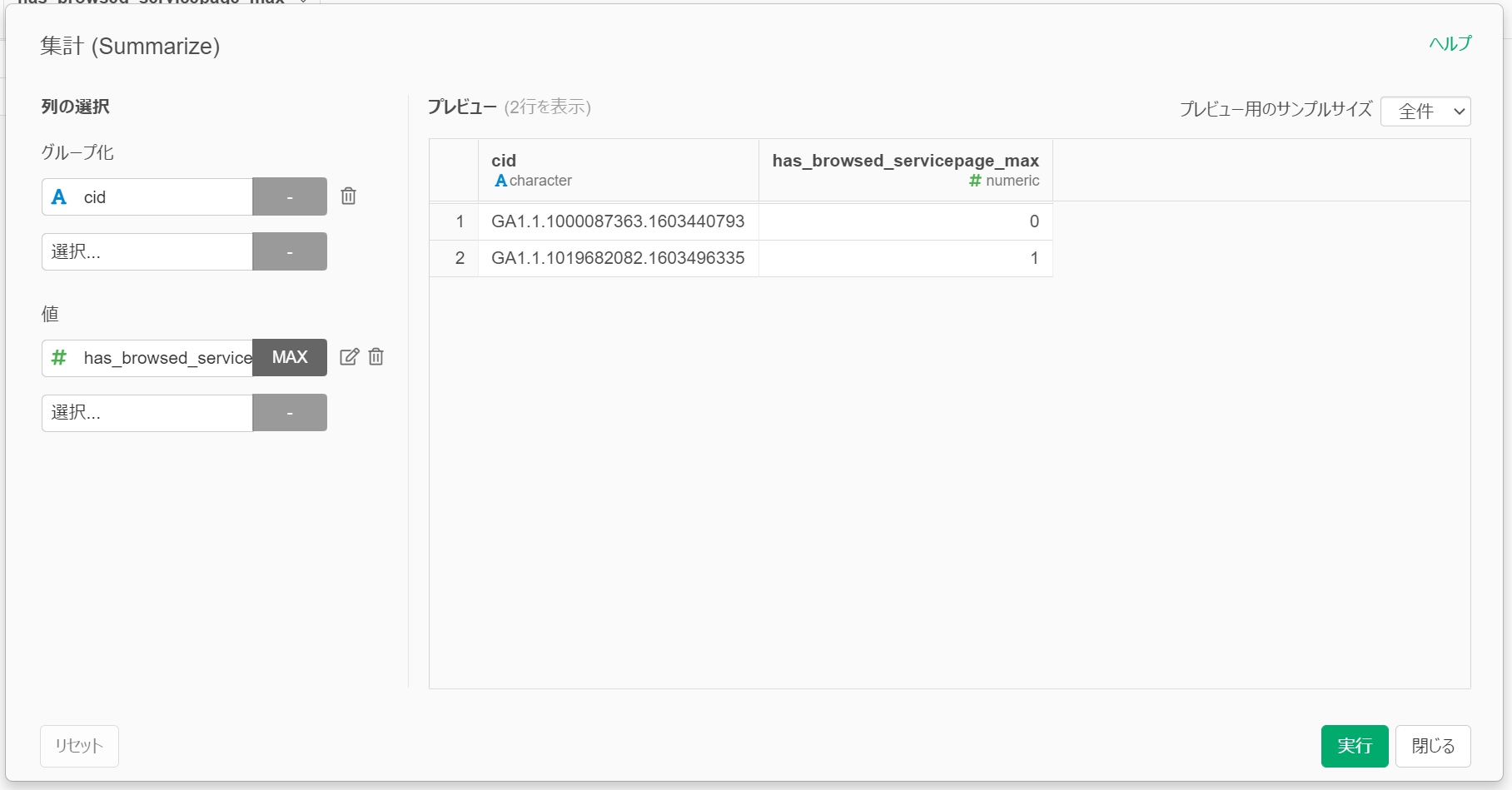
プレビューが出るのが親切ですね。うまく集計できていて、/service/を閲覧していないユーザーは0、閲覧したユーザーは1となっています。
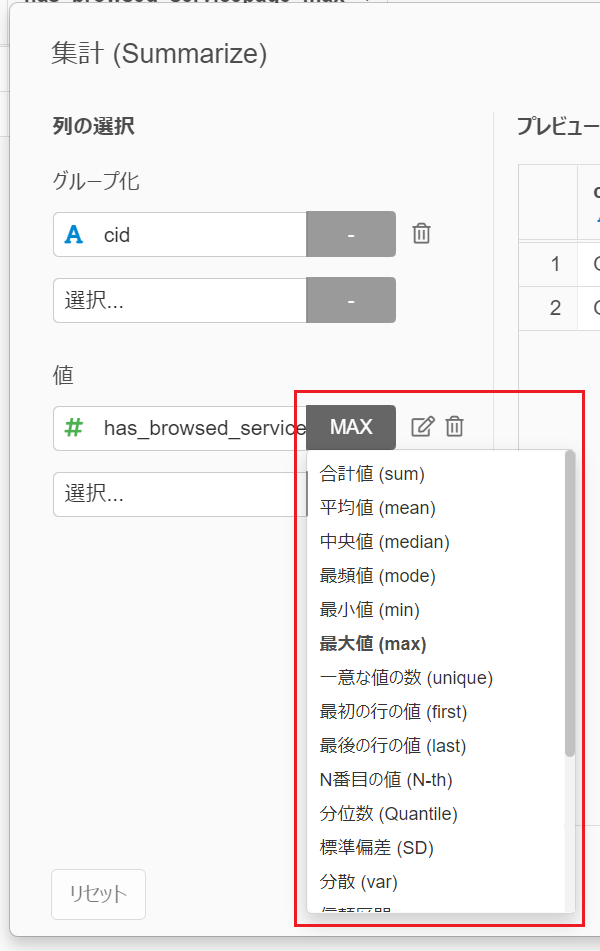
また、今は「最大値」を使って集計していますが、実は集計の方法は以下の通りにたくさん用意されていて、簡単に切り替えることができます。このあたりが非常に強力なのが、私がExploratoryを好きな理由です。
第三ステップ = ブール型にカラムを変更する
今、ユーザーごとに1、あるいは0が格納されている、has_browsed_serivcepage カラムですが、これをTRUEやFALSEといったブール型(ExploratoryはRのUIなので、Rの流儀に従うとLogical型)に変換します。
ここにもExploratoryが用意した関数をUIがありますので、自分で計算式を書かずに変換することができます。
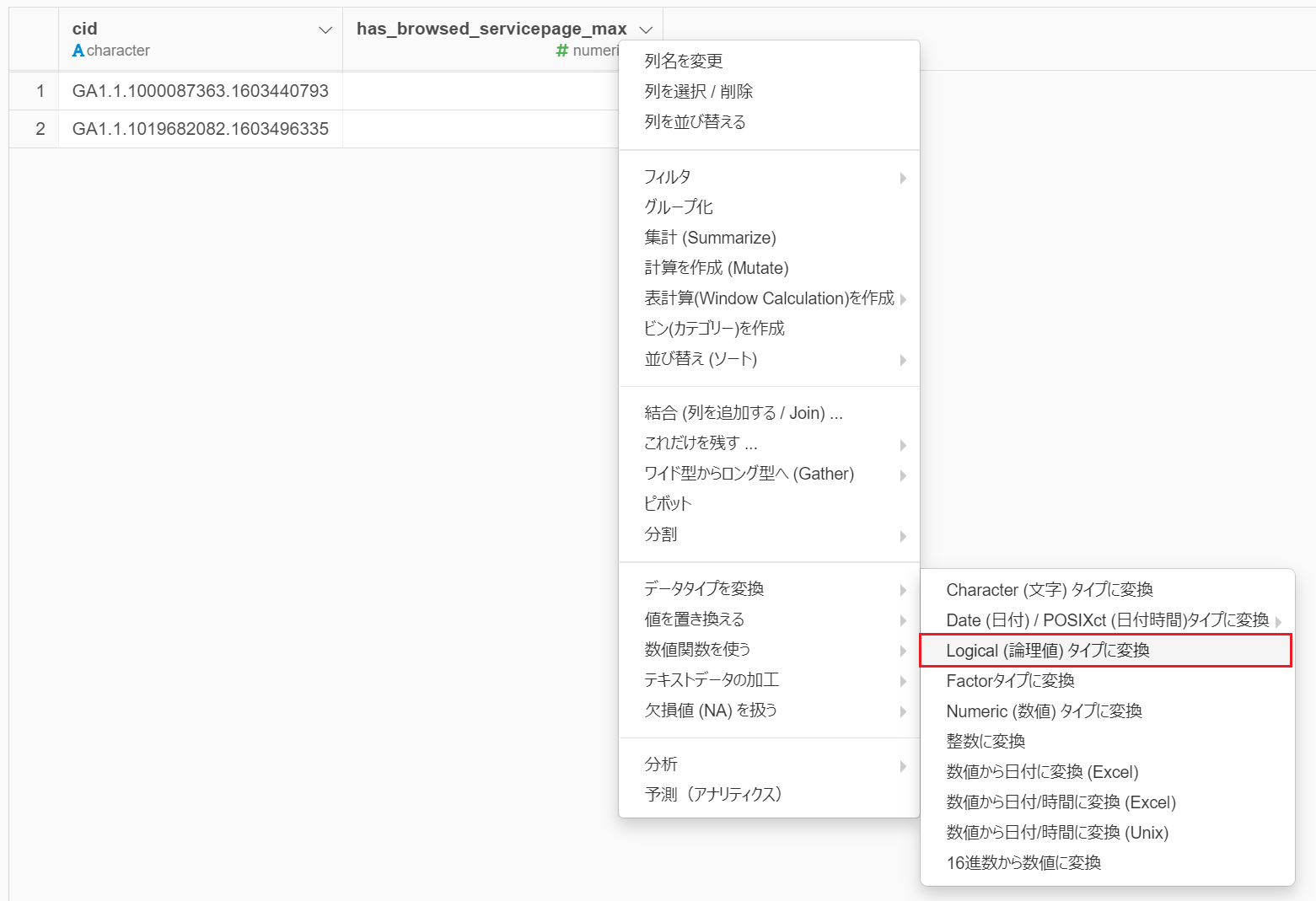
このとき、1がTRUEに、0がFALSEに変換されます。
ロジスティック回帰分析の設定
同様に、ユーザーごとに、お問い合わせという「コンバージョンを起こしたかどうか?」も取得したら、あとは、以下の操作でロジスティック回帰分析を回すだけです。
- アナリティクスタブ(上部の緑のタブ)を選択
- タイプに「ロジスティック回帰」を選択
- 目的変数に「コンバージョンしたかどうか?」のLogical型カラムを選択
- 予測変数に「サービスページを閲覧したユーザーかどうか?」のLogical型カラムを選択
- 実行ボタンをクリック
結果 – 予測タブ
予測タブは以下の通りに出力されます。
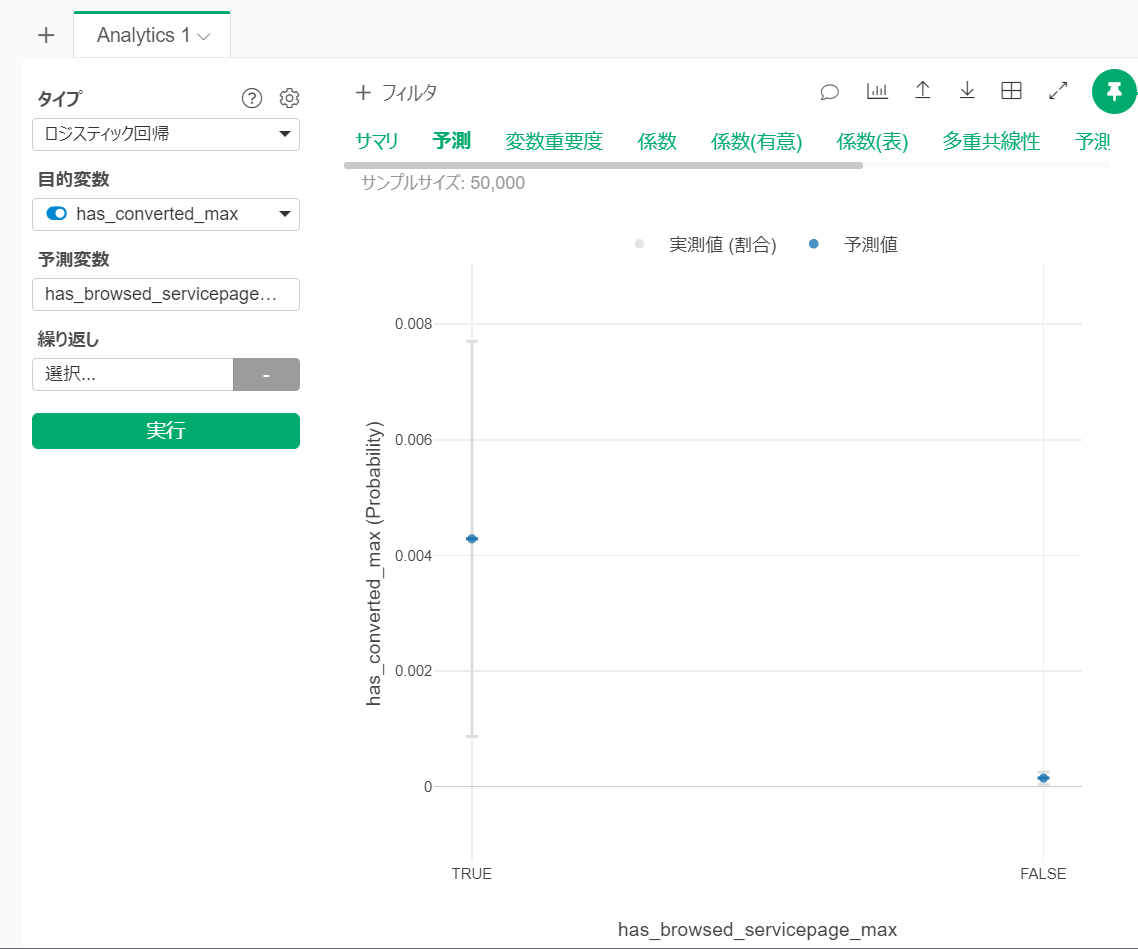
has_browsed_serivcepage_maxがTRUE、つまりサービスページを閲覧したユーザーのコンバージョン率を示しているのが左側のエラーバーです。サービスページを閲覧していないユーザーのコンバージョン率はFALSEで示されている右側のエラーバーとなります。
なぜ、1点でなく、上下に「ヒゲ」が出ているのか?といえば、「区間推定」をしていて、その「信頼区間」を示しているからです。
このチャートから、以下の3点が分かります。
- サービスページを閲覧したユーザーの方がそうでないユーザーよりもコンバージョン率が高いこと
- エラーバーはサンプルサイズの小さい「TRUE」の方が長く伸びていること
- ただ、そのヒゲを含めても、エラーバー(95%信頼区間)が、TRUEとFALSEで被っていないこと
この時点で、サンプルサイズを加味しても、統計的に、サービスページの閲覧はコンバージョンを起こすことに対して効いている。と判断できます。
結果 – 係数(表)タブ
係数表タブでは、詳細なデータが表示されます。
オッズ比は、サービスページを閲覧することが、閲覧しないことに比べて、何倍コンバージョンへの至りやすいかを示しています。
また、P値は、このような結果が偶然でる可能性を示しています。一般的には0.05以下で「有意」(=統計学的に、データのゆらぎを加味しても差がある)とされるしきい値です。
この例ではかなり小さいので、P値については問題ありません。

オッズ比からは、サービスページを閲覧するユーザーは、閲覧しないユーザーに比べて、約30倍もお問い合わせをする確率が高いことが分かりました。







