
マーケティングは定量調査と定性調査を組み合わせて分析することが重要です。
中でも定性調査に関してはSNS投稿、オンラインレビュー、アンケートの自由回答といった、膨大な「テキストデータ」が日々生成されており、そこに含まれる「ユーザーの本音」や「潜在的なニーズ」をどう読み取るかが、企業の成長を左右する重要な鍵となっています。
多くの企業では、以下のような課題を抱えています。
- アンケートの自由記述欄に多くの回答が集まるが、ざっと目を通すだけで終わってしまう
- SNSやレビューの投稿データを渡されても、うまくレポートとしてまとめられない
このような「定性的データの活用不足」は、貴重な顧客インサイトを取りこぼす要因になっています。これらの課題を解決する有効な手段が、「テキストマイニング分析」です。
テキストマイニングの基礎とKH Coder
テキストマイニングとは
テキストマイニングとは、大量の文章データの中から有用な情報を抽出・可視化する技術です。たとえば、頻出語の抽出やワードクラウド、共起ネットワークの作成などにより、ユーザーの傾向や関心の構造を視覚的に把握できます。
テキストマイニングというと専門的な印象を持たれがちですが、実は「KH Coder」という無料ツールを使えば、誰でも手軽に始めることが可能です。本ブログでは、KH Coderを使った簡単な分析手法を紹介していきます。
KH Coderとは
KH Coderは、テキストマイニングを行うための無料の分析ツールです。特に日本語の処理に優れており、大学や研究機関はもちろん、企業のマーケティング部門でも広く利用されています。
- 自然言語処理・統計分析・可視化の機能を統合
- 自由記述の分析に強く、SNSやアンケート、口コミなどの「定性データ」の可視化に最適
- 誰でも無料で使える「Starting Edition(無料版)」あり
言葉の分析がマーケティングの精度を高める
マーケティングでは、顧客の行動や傾向を「数字」で捉えることが一般的ですが、そこに表れない「言葉」=顧客の声・感情を理解することも同じくらい重要です。
テキストマイニングは、この“言葉”に隠れたインサイトを抽出し、次のような場面で有効に活用できます。
テキストマイニングが活きる3つのシーン例

今回は、この中でも初心者でも始めやすく、かつ活用効果の高い「③ 顧客の感情把握」の場面を想定して、具体的な分析方法をご紹介します。
口コミ分析の実践 – ホテル業界のケーススタディ
想定シナリオ:ホテル業界での活用ケース
テキストマイニングの実用イメージを掴んでいただくために、以下のような本ブログでは以下のシーンを想定して分析方法を紹介します。
- 業種: 日本国内のホテル業界
- 登場人物: ホテルのマーケティング部門に所属する社員
- ミッション: 経営層から、「SNSや口コミサイトに寄せられた顧客の声を分析し、サービス改善や集客施策の改善点を報告せよ」と指示される
- 分析対象: SNSやレビューサイトのフリーテキスト(自由記述)部分
数値では見えにくい「お客様の本音」を、テキストマイニングでどのように可視化し、マーケティング改善へとつなげていくかが重要です。実際に「KH Coder」を使った分析手順と可視化例をご紹介します。
KH Coderを用いた分析の流れ
実際に無料で使えるツール「KH Coder」を用いて、具体的な分析を進めていく準備に入ります。
手順1. KH Coderのインストールとセットアップ
KH Coderのインストール方法は、公式サイトに詳細が掲載されていますが、本ブログでは導入前に知っておきたいポイントをまとめてご紹介します。
ー必要環境
- OS:Windows 10以降を推奨(Macの場合は仮想環境の構築が必要)
- ストレージ:最低50MB以上の空き容量が必要
ー注意点(無料版を使用する場合)
KH Coderの無料版「Starting Edition」にはいくつかの制限があります。
- 分析対象はテキストファイルの最初の100段落まで
- 強制抽出語・無視語の指定はそれぞれ1語のみ
- 品詞(名詞・形容詞など)の絞り込みができない
- 単語の前処理機能に制限あり
業務で本格的に活用する場合は有料版を検討してもよいですが、まずは無料版でも十分に基本的な分析は可能です。
補足:KH Coderが対応する基本データ形式
テキストマイニングを効果的に行うには、事前にデータ形式を正しく整えることが極めて重要です。KH Coderでは、主に以下の2つのファイル形式が利用できます。
① CSVファイル(複数データの整理に便利)
- 各行が1件のデータを表現
例:アンケート回答、レビューコメントなど - 一般的に「ID」「コメント内容」「日付」などを1行にまとめておくと管理しやすく、後の集計やフィルタリングもスムーズです
例)複数の顧客意見を一括管理・比較したいとき
(アンケート結果分析や口コミレビューの整理など)
② TXTファイル(自由な文章分析に便利)
- テキストがひと続きになった形式
例:記事本文、SNS投稿の連続データなど - ファイル全体が1つの分析対象として読み込まれるため、長文をまとめて解析したい場面に適しています
例)ブログ記事、SNSまとめ投稿、通話ログなどの全文分析
「CSVにするかTXTにするか」というファイル形式の選定は、分析の目的によって変わります。
- 複数の意見を個別に比較・集計したい → CSV
- 全体の流れやキーワードの傾向をざっくり捉えたい → TXT
特にマーケティングでは、「定性的な声を数値化・可視化」する工程が重要なため、事前のデータ整理が成功の鍵を握ります。
手順2. データ準備と前処理(ノイズ除去・データ整形)
テキストマイニングの精度は、「どれだけ適切にデータを整備できるか」に大きく左右されます。特にSNSや口コミのような“自然言語”を扱う場合、事前処理の丁寧さが分析結果の質に直結します。
ーStep1:分析用データを準備する
今回のデモでは、ChatGPT 4oを活用して生成したダミーの口コミデータを使用します。実務でも同様の形でデータを整えることが重要です。

ーStep 2:テキストデータの前処理
▼Step2.1 ノイズの除去
テキストデータには、以下のようなノイズ(分析を妨げる要素)が含まれていることがあります。
- 文法ミスや表記揺れ
- URLや絵文字などの不要情報
KH Coderは基本的なクリーニングも可能ですが、あらかじめノイズを除去・修正しておくことで分析効率が格段に向上します。
▼②Step2.2 データの分割・整形
大量のデータを一括で処理するのは非効率です。
そのため、たとえば「1,000行ずつに分ける」「属性ごとにセグメント分けする」などの処理を行うと、後の分析がスムーズになります。
- セグメント:属性やテーマごとに分割
- 別列の追加:年代、来訪目的、投稿媒体などの変数を加えることでより深い分析が可能に
実際のデータ例
以下は、ChatGPTで生成したダミー口コミデータの一例です。

このように、ID・コメント・日付といった構造化されたデータに整えることで、KH Coderにそのままインポートできるようになります。
手順3.KH Coderへのデータ取り込み(プロジェクト作成、CSVの読み込み)
ここからは最初のステップとなるプロジェクトの作成とデータの読み込み(インポート)手順を、スクリーンショット付きでわかりやすく解説します。
ーStep 1:プロジェクトの作成
KH Coderを起動すると、画面上部にメニューバーが表示されます。まずは以下の手順でプロジェクトを新規作成します。

■ 手順:
- ①KH Coderを起動
- ②メニューバーの「プロジェクト」から「新規」を選択
- ③任意のプロジェクト名を入力し、保存先フォルダを指定
- ④分析対象となるテキストデータ(CSVまたはTXT)を指定
分析用の環境が立ち上がります。
▷ 補足:プロジェクトとは?
KH Coderでは、1つの分析対象データを「プロジェクト」として管理します。分析条件や処理履歴が自動的に保存されるため、あとから再開したり、条件を変えて再分析するのも簡単です。
ーStep 2:CSVファイルのインポート設定
プロジェクトの新規作成を選んだあとは、以下の手順でテキストデータを読み込みます。
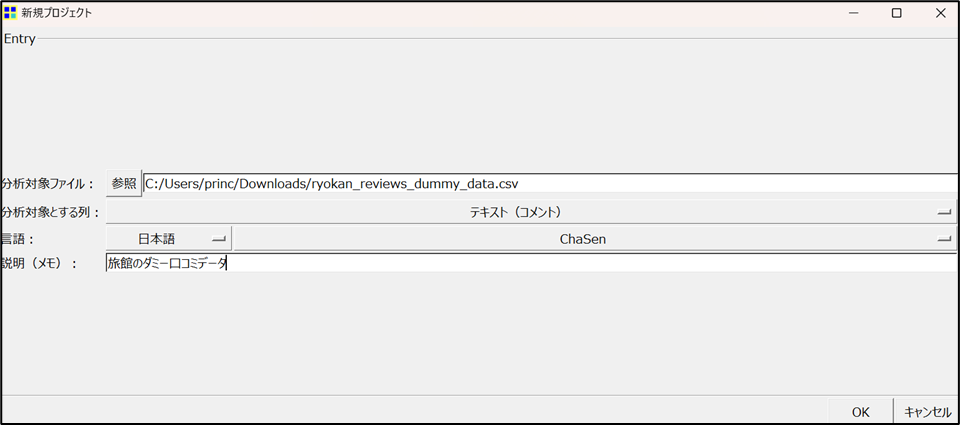
■ 操作手順:
- ①「参照」ボタンから分析対象のCSVファイルを選択
- ②「分析対象とする列」を指定(例:
テキスト(コメント)など) - ③「言語」は日本語を選択(日本語の形態素解析エンジンを使用するため)
- ④必要に応じてメモ欄に説明を記入(例:旅館の口コミデータなど)
- ⑤「OK」ボタンを押してアップロード完了
読み込みが完了したら、テキストを分析に適した形に整える前処理を行います。KH Coderの中で以下の操作を行うことで、分析の精度が高まります。
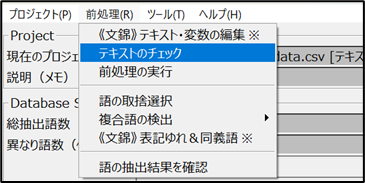
■前処理の手順:
1. メニュー「前処理」>「テキストのチェック」
→ データ内容に不備がないかを確認
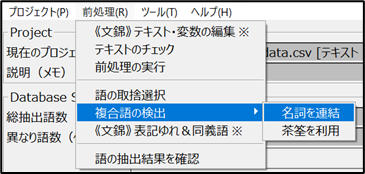
2.「前処理」>「名詞の連結」
→ 「朝食ビュッフェ」「大浴場」などの複数語句を1語として扱う設定
3.「前処理の実行」をクリック
→ 設定内容を反映して、形態素解析(品詞分解)を開始
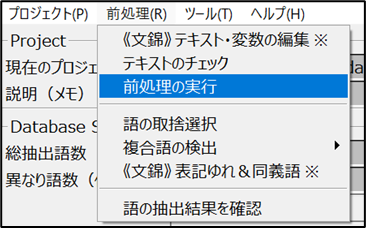
このステップを行うことで、KH Coderがテキスト内の単語を正確に認識・抽出できるようになります。
テキストマイニング分析手法と考察
ここからは実際に分析をしていくフェーズです。今回ご紹介するのは、テキストマイニングの中でも最も基本的かつ汎用性の高い手法、「単語の頻度分析」です。
口コミやアンケートの中で、どのような言葉が多く使われているのかを可視化することで、顧客の関心や不満の傾向を読み取ることができます。
単語の頻度分析
頻度分析では、対象テキストの中に登場する単語の出現回数を集計し、上位の単語を一覧化します。
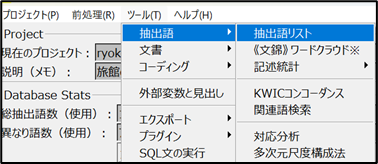
- ①メニューバーの「ツール」→「抽出語」→「抽出語リスト」を選択
- ②単語の出現頻度がリスト化され、グラフ付きで表示されます
単語の頻出傾向を把握することで、以下のような洞察が得られます:
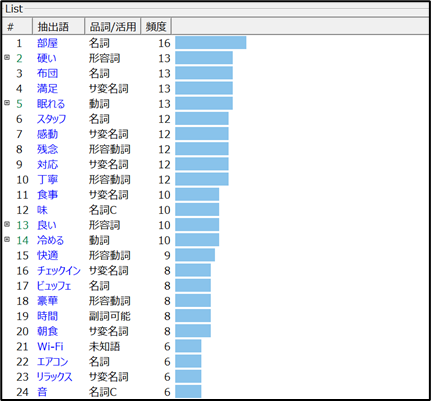
<ポジティブ or ネガティブの傾向把握>
例:
- 「満足」「快適」などのポジティブワードが多ければ、全体の満足度が高い可能性
- 「残念」「うるさい」などのネガティブワードが多ければ、改善点が浮き彫りに
<改善点や強みの発見>
例:頻出語「布団」「スタッフ」「丁寧」などから、具体的に評価されているポイントや改善ニーズが見えてくる
ー実際の分析結果からの考察
ダミーの旅館口コミデータを使った頻出語分析では、以下のような傾向が見えました。
「現段階ではホテルの評価は総じて良すぎず悪すぎず。ホテルの利用者は『部屋の品質』を気にしている傾向があり、評価があまり良くない時期にある。」
頻出語「部屋」「布団」「チェックイン」などの出現回数や、関連コメントの内容から、施設面に対する声が多い=改善ポイントのヒントが多い領域だと判断できます。
共起ネットワーク分析
次は一歩進んで、「どの単語とどの単語が一緒に使われているか」を可視化する手法、共起ネットワーク分析をご紹介します。
共起ネットワーク分析とは、単語同士の共出現関係(=一緒に使われる頻度)をもとに、関係性の強弱をネットワーク図として可視化する手法です。
たとえば、
- 「部屋」と一緒に「清潔」「広い」「古い」が頻出していれば、「部屋に関する印象」が見えてきます。
- 「スタッフ」と「丁寧」「対応」「不親切」などがつながっていれば、サービス面の評価傾向が明らかになります。
ーKH Coderでの操作手順
① 基本表示手順
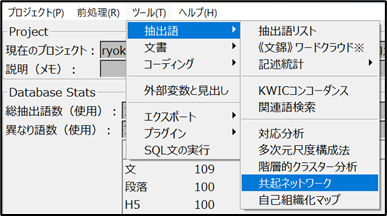
- メニューバーから「ツール」>「抽出語」>「共起ネットワーク」を選択
- リストが表示され、共起する語のネットワークが生成されます
② 詳細設定(視覚強化)
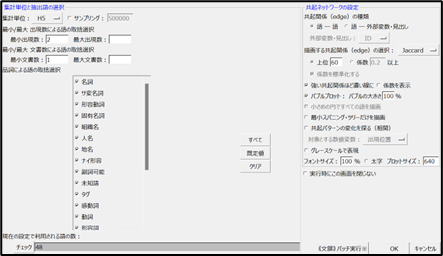
「共起ネットワークの設定」画面で、以下の設定を推奨
- 「強い共起関係ほど濃い線に」にチェック
- 「係数を表示」にチェック
これにより、単語間のつながりの強弱が直感的に分かるネットワーク図として可視化されます出力結果から、実際にどのようなインサイトが得られるのか、ポジティブ/ネガティブ要素に分けて分析していきます。
ーネットワーク図の見方と活用ポイント
生成された共起ネットワーク図では、以下のような情報が視覚的に把握できます。
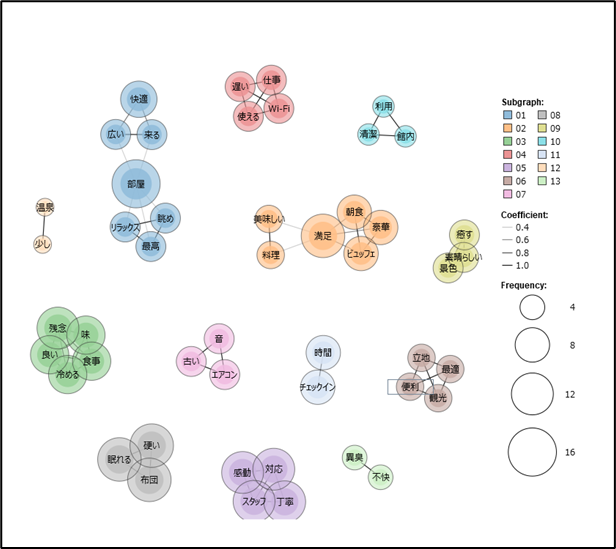
- 円の大きさ:単語の出現頻度
- 線の太さ:単語同士の共起関係の強さ
- 色の違い:意味的なグループ(サブカテゴリ)
これにより、ただの「単語の羅列」では見えにくかった言葉の関係性や顧客の捉え方が浮き彫りになります。
可視化された“声”から読み解くインサイト
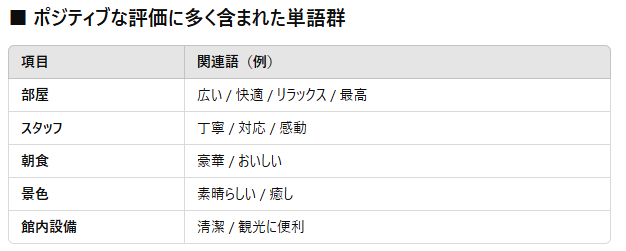
これらは満足度が高く、他の顧客にも訴求すべき強み(アピールポイント)として活用できます。

これらは改善の優先度が高い課題領域と捉えることができます。
ホテル口コミ分析からの2つの改善提案
これまでの分析で、KH Coderを活用した「頻度分析」や「共起ネットワーク分析」から、顧客がホテルに対して抱くポジティブ/ネガティブな評価軸を明らかにしてきました。
今回は、その分析結果を踏まえた改善施策の具体的なアイデアをご紹介します。
改善提案1. 安らぎ感とリラックス空間の強化
■背景
「部屋」や「スタッフ」「朝食」などにポジティブな評価が多く見られましたが、“満足”で終わっているお客様に、あと一歩の感動を届けるには?という視点が重要です。
■ 課題
現状の満足度は高いが、「安らぎ」や「癒し」の印象をさらに強化できる余地あり。
■ 改善施策のアイデア
- 客室の照明を調光式にし、昼夜で雰囲気を演出できるようにする
- アロマディフューザーやリラクゼーション音楽をオプション提供
- 客室内にストレス軽減アイテム(マッサージチェアや目隠しキットなど)を設置
- 広告LPで高評価の客室イメージを強調し、視覚的に“癒し”を訴求
改善提案2. 設備の老朽化に対する不満への対応
■ 背景
「布団が硬い」「エアコンが古い」「Wi-Fiが遅い」などの不満がネットワーク分析上でも顕著に見られました。
■ 課題
施設の老朽化に起因するネガティブな印象が、全体の評価を下げるリスクに。
■ 改善施策のアイデア
- エアコン等の設備を最新型に入れ替え、省エネ性もアピール
- 古くなった家具や内装を、ターゲット層に合わせたデザインでリニューアル
- 大浴場や共用スペースの清掃頻度を見直し、「清潔感」の強化を図る
まとめ:データに基づいた“納得感ある改善案”が鍵
テキストマイニングは、単なる数値ではなく顧客の“言葉”に根ざした改善インサイトを引き出せるのが最大の強みです。今回ご紹介した施策は、すべて口コミデータに根拠を持つもの。社内稟議や企画提案の場でも説得力のある資料として活用できます。
プリンシプルでは定量データと定性データの分析のご支援が可能です。データ分析でお困りの方は是非お気軽にお問い合わせください。










