
弊社では最近LookerStudioとBigQueryの連携についてお問い合わせ頂くことが増えており、関心が高まっていることを実感しております。その中でもよく、従量課金サービスだから運用面に不安があるといった声を頂くことが多いです。
今回はLSとBQを利用した場合に発生する費用、予期せぬ課金を招くアンチパターンと対策を紹介します。
BigQueryの課金体系
BigQueryのシステム構成は以下の2つに分かれており、それぞれ異なる課金体系を持ちます。
- データを貯めるストレージリソース:$0.04/GiB・月
- クエリを発行してデータを抽出するコンピュートリソース:$6.25/TiB
※2024/2/7時点のUSリージョンの料金
※ストレージ料金はActive physical storageの料金を参照
上記の通り、クエリの発行の方が単価が高く、利用状況によって費用が大きく変わってきます。
たとえば、データをたくさん貯めていても、分析での利用がなく、クエリ発行が発生しない場合はストレージ料金のみが課金され利用料金は低額に。反対に、蓄積されているデータが少なくても頻繁にクエリを発行する場合、都度課金が発生し利用料金が高額になる場合があります。
LSにBQを連携すると起こること
LSはデータ読み込みの際にBQに対してクエリを発行します。BQはコンピュートリソースを利用してデータを抽出するため、BQ側でクエリの課金が発生します。
具体的には以下の項目などで、LSのコンポーネント(グラフ・表・フィルターなど)ごとにデータ抽出が発生します。
レポート作成時
- 新しいグラフの描画
- ディメンション・指標の追加
レポート閲覧時
- レポートの初回読み込み
- データ期間の変更
- データのフィルター
- オプション指標の表示
正確には、LSとBQを接続するとデータをキャッシュしてくれる領域が無料で1GB割り当てられており、キャッシュされていないデータを読み込む際に、新たなデータ抽出が発生します。
また、データの容量が大きい程クエリでの抽出頻度も多くなり、費用増大の原因になります。さらに、データ表示に時間がかかるため、レポートの利用者にとってはストレスがかかります。
アンチパターンと解決策
上記のLSの仕様上BQから、大きなデータを読み込むことは非推奨となります。
中でも見落としがちなパターンとして以下の2パターンを紹介します。
アンチパターンA:カスタムクエリでRowデータを読み込む
GA4のRowデータなど大容量のデータをカスタムクエリで接続すると、LSはキャッシュ外の大量のデータを抽出する度にクエリを発行。気付いた時には膨大な課金額になる可能性が高い。
アンチパターンB:Rowデータの読み込みが発生するビューを接続する
LSにビューを接続する際もパターンAと同様に、BQに対してRowデータを参照するクエリを発行するため、意図しない課金額増加につながる。
どちらもデータ更新をLS側で制御できるため便利ではありますが、費用対効果の面からオススメできません。
解決策1:中間テーブルを作成する
連携するクエリ結果を中間テーブルとして作成してから連携することで、データ連携の際に発生するクエリ量を削減できます。
たとえば以下ように、カスタムクエリを利用した場合はクエリは最大100GBなのに対して、レポート用に事前集計した中間テーブルを利用すると最大5GBと大幅にデータの読み込み量が削減されます。
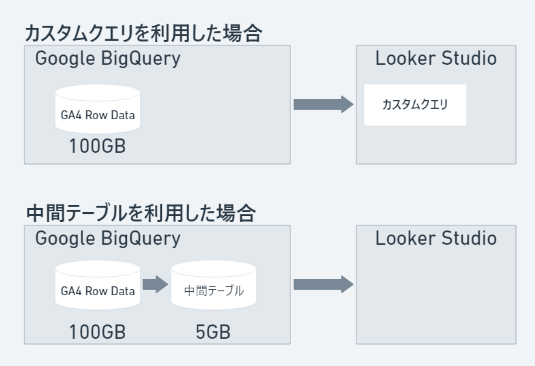
クエリ結果をテーブルとしてBQに作成するだけなので、今すぐ実行できる効果的な方法です。しかし、カスタムクエリ・ビューを利用した場合にできていたLSでの制御が使えないため、データを最新の状態に更新する部分に課題が残ります。
解決策2:クエリをスケジュールする
BQにはクエリを事前にスケジュールして実行する機能が備わっています。こちらを利用すると「毎日朝10時にテーブルを更新する」など更新作業を自動化できます。
設定方法はシンプルで、コンソール上で完結します。
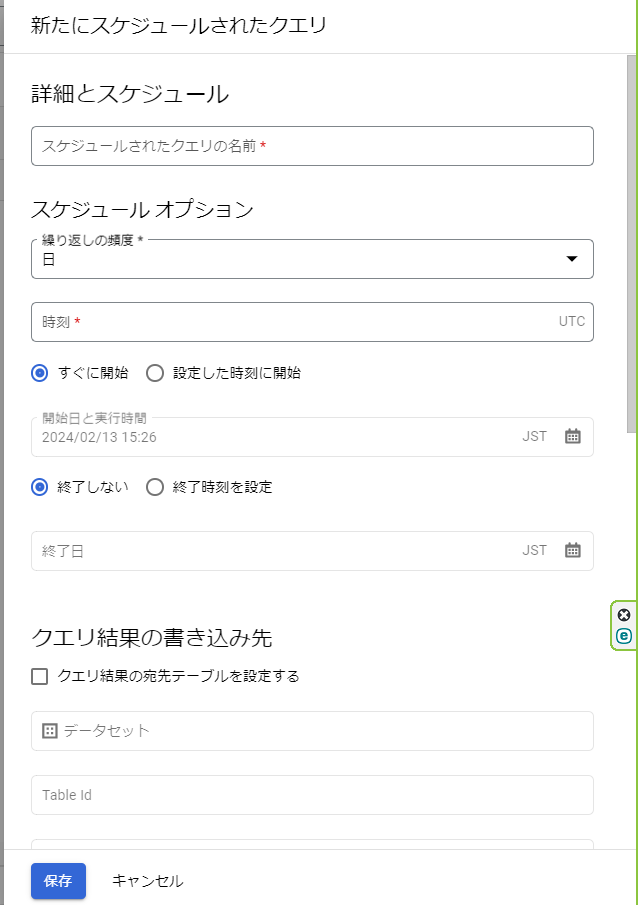
[設定方法]
①スケジュール設定したいクエリをBQコンソール上に入力する。
②コンソール上メニューから「スケジュール」をクリック。

③以下のようなポップアップが表示されるので、スケジュールするクエリの保存名、実行時間、保存先のテーブルなどの情報を入力し、最下部の「保存」ボタンをクリックして完了。
まとめ
この記事ではLSとBQを利用した場合に発生する費用、予期せぬ課金を招くアンチパターンと対策を紹介しました。LSとBQを連携する際には連携方法に注意が必要ということをご認識頂けましたでしょうか?
最後に、注意点と解決策をまとめます。
- カスタムクエリ、ビューを接続するとクエリ課金量が増大する可能性が高い。
- 接続するデータには事前集計した、中間データを用いる。
- 中間データの更新はスケジュール機能を使えば自動化できる。
もっと効率的・経済的にデータを連携するには?
もっと効率的・経済的にデータを連携するにはどうすればよいのでしょうか?方法としては、データのパーテーション設定する、BIエンジンの利用、データパイプラインを見直して共通クエリをテーブルかするなど、いくつかの方法があります。
次回のブログで引き続き紹介しますので、ぜひチェックしてみてください。







