
本記事で触れているGoogleアナリティクスは、ユニバーサルアナリティクス(UA)を前提としています。
GA4を対象とした記事ではございませんので、ご注意ください。
「Google アナリティクスで計測した内容を、他のデータと統合して分析したい」
Google アナリティクスを活用されているお客さまから、しばしばいただくご要望です。
アナリティクスと、データを集約するシステムやサービス(たとえば、Google BigQuery)を連携するには、特別なプログラムを開発する必要があるのではないか――そんなふうにお考えの方が多いかもしれません。ですが、適切なツールを使うことで、プログラム開発をすることなく、データの連携は実現できます。
今回は、データ転送ツール「Embulk」を使って、Google アナリティクスの計測値をGoogle BigQueryに転送する手法を紹介します。
【目次】
データ転送ツール「Embulk」とは?
Embulkは、データの転送を助けるソフトウェアです。
Embulk: Pluggable Bulk Data Loader.
オープンソース・ソフトウェアとして公開されており、誰でも使うことができます。開発を主導しているTreasure Data社はデータ・ソリューション分野で高い実績があり、信頼性や将来性にも期待できます。
Embulkは、以下のような特徴を持っています。
- プラグイン・アーキテクチャを採用しており、入力元や出力先を柔軟に組み合わせたり、フィールド名や値をフィルターで加工したりできる。
- ビッグデータを扱えるように、並列処理や分散処理を備えている。
- トランザクション制御を備え、エラー発生時にも整合性を保つことができる。
動作環境
Embulkは、Javaアプリケーションです。
そのため、LinuxやBSDだけでなく、WindowsやMacでも動作させることができます。
キャラクタ・ユーザー・インタフェース
Embulkは、キャラクタ・ユーザー・インタフェース環境(CUI環境)で実行するソフトウェアです。Windowsであれば「コマンドプロンプト」、Macであれば「ターミナル」といったコマンドライン・インタプリタ・アプリケーションから呼び出して使用します。
インストール
インストールの方法を、公式ドキュメントに添って述べます。
Embulk documents – Quick Start
Embulkの動作には、Java言語の実行環境が必要です。
まずは、Javaの実行環境(JRE: Java Runtime Environment)をインストールしましょう。
Java SE – Downloads | Oracle Technology Network | Oracle
Linux & BSD & Mac
以下の4行のコマンドで、ユーザーホーム・ディレクトリにEmbulkがダウンロードされ、実行可能な状態になります。
curl --create-dirs -o ~/.embulk/bin/embulk -L "http://dl.embulk.org/embulk-latest.jar"
chmod +x ~/.embulk/bin/embulk
echo 'export PATH="$HOME/.embulk/bin:$PATH"' >> ~/.bashrc
source ~/.bashrcMacをお使いの場合、標準のままのターミナルでは、上記のコマンド実行ではインストールが適切に完了せず、Embulkの実行時にエラーが発生するかもしれません。その場合は、~/.bash_profileに環境変数PATHの記述を追加しましょう。あるいは、上記のコマンドを使用せずに、Homebrewを使ってインストールしても良いでしょう。
Windows
以下のコマンドで、コマンド実行時の作業フォルダにEmbulkがダウンロードされます。
PowerShell -Command "& {Invoke-WebRequest http://dl.embulk.org/embulk-latest.jar -OutFile embulk.bat}"
Embulkを複数のプロジェクトで使用する場合は、C:¥Program FilesフォルダにEmbulkフォルダを設け、環境変数の設定を変更してPATHに追加すると良いでしょう。
実行
Embulkは、規定のサブコマンドとオプションを指定して呼び出すことで動作します。
サブコマンドの一部を紹介します。
- embulk example
Embulkの動作を試すための、例となる設定ファイルや転送元ファイルを生成します。 - embulk run <設定ファイル>
設定ファイルの内容にのっとって、データ転送が実行されます。 - embulk preview <設定ファイル>
データ転送をプレビューします。出力先への転送を実行することなく、入力元とフィルター処理の設定を適用した結果を確認できます。 - embulk guess <部分的な設定ファイル> -o <設定ファイル>
設定ファイルの不足部分を補います。入力元に由来するフィールドのデータ型を指定する際に便利です。 - embulk selfupdate
Embulkのプログラム・ファイルをアップデートします。 - embulk gem<install | list | help>
プラグインのインストールや、インストール済みのプラグインの一覧表示を実行します。
サブコマンドやオプションを省略して「embulk」を実行すると、ソフトウェアのバージョンと、サブコマンドとオプションの一覧が表示されます。
データ転送の準備・設定
さて、それではGoogle アナリティクスの計測値をGoogle BigQueryに転送する方法を説明していきます。
下準備として、Google APIs(Google Cloud Platform)のプロジェクトの設定と、Embulkの設定ファイルの作成を実施します。
Google APIsのプロジェクトの設定
Google アナリティクスやBigQueryをEmbulkであつかうためには、Google APIs(Google Cloud Platform)のプロジェクトを作成して、API接続の認証情報と使用するライブラリを設定する必要があります。
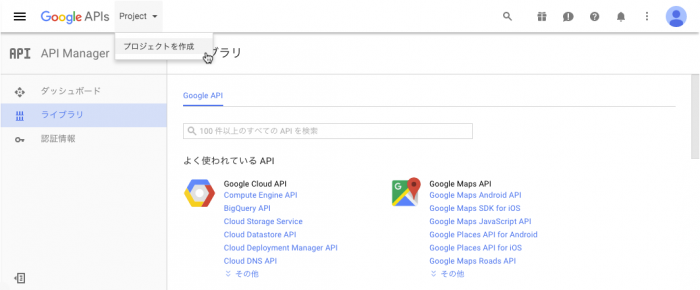
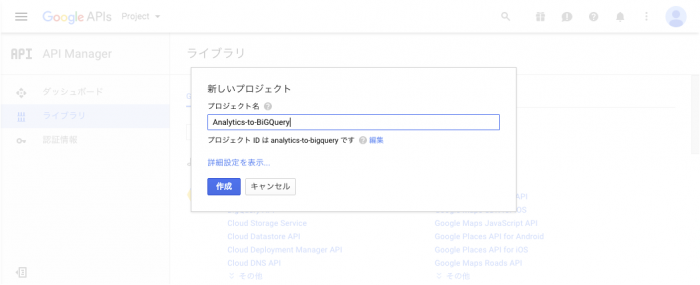
1. プロジェクトの作成
Google API Consoleにアクセスして、新規プロジェクトを作成します。
Google API Console
2. 認証情報の設定
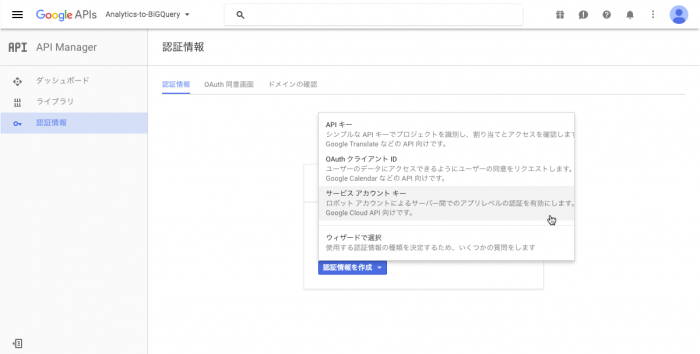
作成した新規プロジェクトについて、「認証情報」メニューから、「サービス アカウント キー」を作成します。
なお、ここで設定するアカウントID(メールアドレス)は、Google アナリティクスの閲覧権限の設定にも使用します。
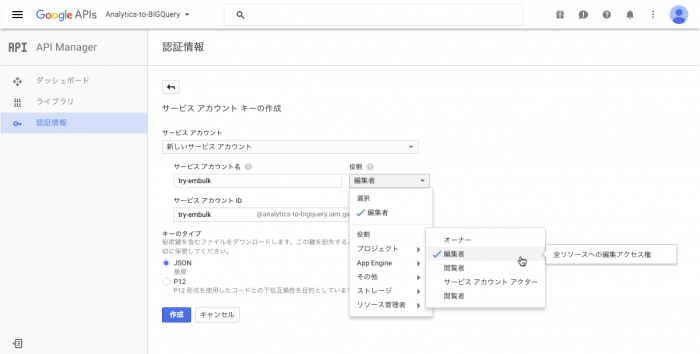
「キーのタイプ」には、「JSON」を選択します。作成される「秘密鍵」ファイルは、Embulkから使用します。Embulkを実行する環境の適当なディレクトリ(フォルダ)に配置してください。
3. Google APIライブラリの適用
「ライブラリ」メニューから、以下の3つのライブラリを有効化します。
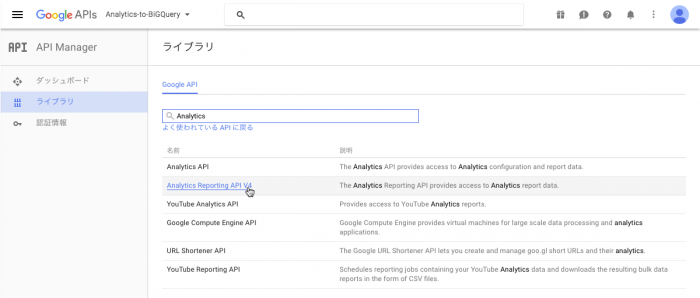
なお、BigQueryを使用するには支払い情報を設定する必要があります。
4. Google アナリティクスの権限の追加
Google アナリティクスの管理画面から、データ転送の対象のビューのユーザーに、「2. 認証情報の設定」で作成したサービスアカウントを追加してください。必要な権限は「表示と分析」です。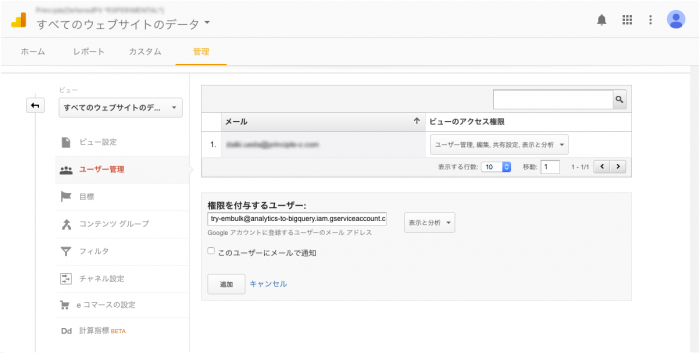
Embulkの設定ファイルの作成
Embulkを使って実行したい転送処理の内容は、設定ファイルとして、YAML形式で記述します。たとえばアナリティクスからBigQueryへの転送処理の場合、設定ファイルの内容は、以下のような構成となります。
in:
type: google_analytics
<アナリティクスの認証情報>
<アナリティクスの転送対象の指定>
out:
type: bigquery
<BigQueryの認証情報>
<BigQueryのデータ・セット/テーブルの指定>
今回は、設定ファイルを「analytics-to-bigquery.yml」という名前で作成します。
例として、以下の内容を設定します。
- アナリティクスのビュー(ID: 123456789)から、前日分のページURLごとのページビュー数を取得して…
- BigQueryのデータセット「try_embulk」・テーブル「analytics_pageviews」に転送する。
設定内容をカスタマイズする場合は、後述するプラグインのドキュメントを参照して、設定フィールドごとの役割を把握すると良いでしょう。
Google アナリティクス
以下のプラグインを使用します。
treasure-data/embulk-input-google_analytics: Embulk Input Plugin for Google Analytics
インストール方法(コマンド)
embulk gem install embulk-input-google_analytics
認証情報の適用
in > json_key_contentフィールドに、Google APIsのプロジェクトの設定で生成した「秘密鍵」ファイルの内容を貼り付けます。
in:
type: google_analytics
json_key_content: |
{
"type": "service_account",
"project_id": "....",
"private_key_id": "....",
"private_key": "-----BEGIN PRIVATE KEY-----\n…...\n-----END PRIVATE KEY-----\n",
"client_email": ".....",
"client_id": ".........",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://accounts.google.com/o/oauth2/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": ".........."
}
転送する対象の指定
inフィールドの子要素として、転送する対象であるビューのIDや、集計する期間、ディメンション・指標などを記述します。time_seriesフィールドはプラグインが要求する必須項目で、”ga:date” または “ga:dateHour” を指定します。
in:
type: google_analytics
json_key_content: |
{ …….. }
view_id: 123456789
time_series: "ga:date"
start_date: yesterday
end_date: yesterday
dimensions:
- "ga:pagePath"
metrics:
- "ga:pageviews"
Google BigQuery
以下のプラグインを使用します。
embulk/embulk-output-bigquery: Embulk output plugin to load/insert data into Google BigQuery
インストール方法(コマンド)
embulk gem install embulk-output-bigquery
認証情報の適用
outフィールドの子要素に「auth_method」と「json_keyfile」を記述します。
in:
……..
out:
type: bigquery
auth_method: json_key
json_keyfile: /path/to/google-project-keyfile.json
「json_keyfile」のパス指定を相対パス形式で記述すると、ファイル探索の起点はembulkが実行されるワーキング・ディレクトリとなります。実行ディレクトリが不定の場合は、パス指定を絶対パス形式で記述してもよいでしょう。
データ・セット/テーブルの指定
転送先となる、BigQueryのデータ・セット/テーブルを指定します。今回は、BigQueryの設定を簡略にするため、「auto_create_dataset」オプションと「auto_create_table」オプションを有効にしています。
in:
……..
out:
type: bigquery
auth_method: json_key
json_keyfile: /path/to/google-project-keyfile.json
auto_create_dataset: true
auto_create_table: true
dataset: try_embulk
table: analytics_pageviews
設定ファイルの全体像
in:
type: google_analytics
json_key_content: |
{
"type": "service_account",
"project_id": "....",
"private_key_id": "....",
"private_key": "-----BEGIN PRIVATE KEY-----\n…...\n-----END PRIVATE KEY-----\n",
"client_email": ".....",
"client_id": ".........",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://accounts.google.com/o/oauth2/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": ".........."
}
view_id: 123456789
time_series: "ga:date"
start_date: yesterday
end_date: yesterday
dimensions:
- "ga:pagePath"
metrics:
- "ga:pageviews"
out:
type: bigquery
auth_method: json_key
json_keyfile: /path/to/google-project-keyfile.json
auto_create_dataset: true
auto_create_table: true
dataset: try_embulk
table: analytics_pageviews
データ転送の実行
いよいよEmbulkの実行です。
プレビュー
まずはプレビューです。設定ファイルを指定して、previewサブコマンドを実行してみましょう。
embulk preview analytics-to-bigquery.yml
ここまでの設定作業の内容が適切であれば、アナリティクスから取得されたデータの先頭部分が、表形式で表示されます。
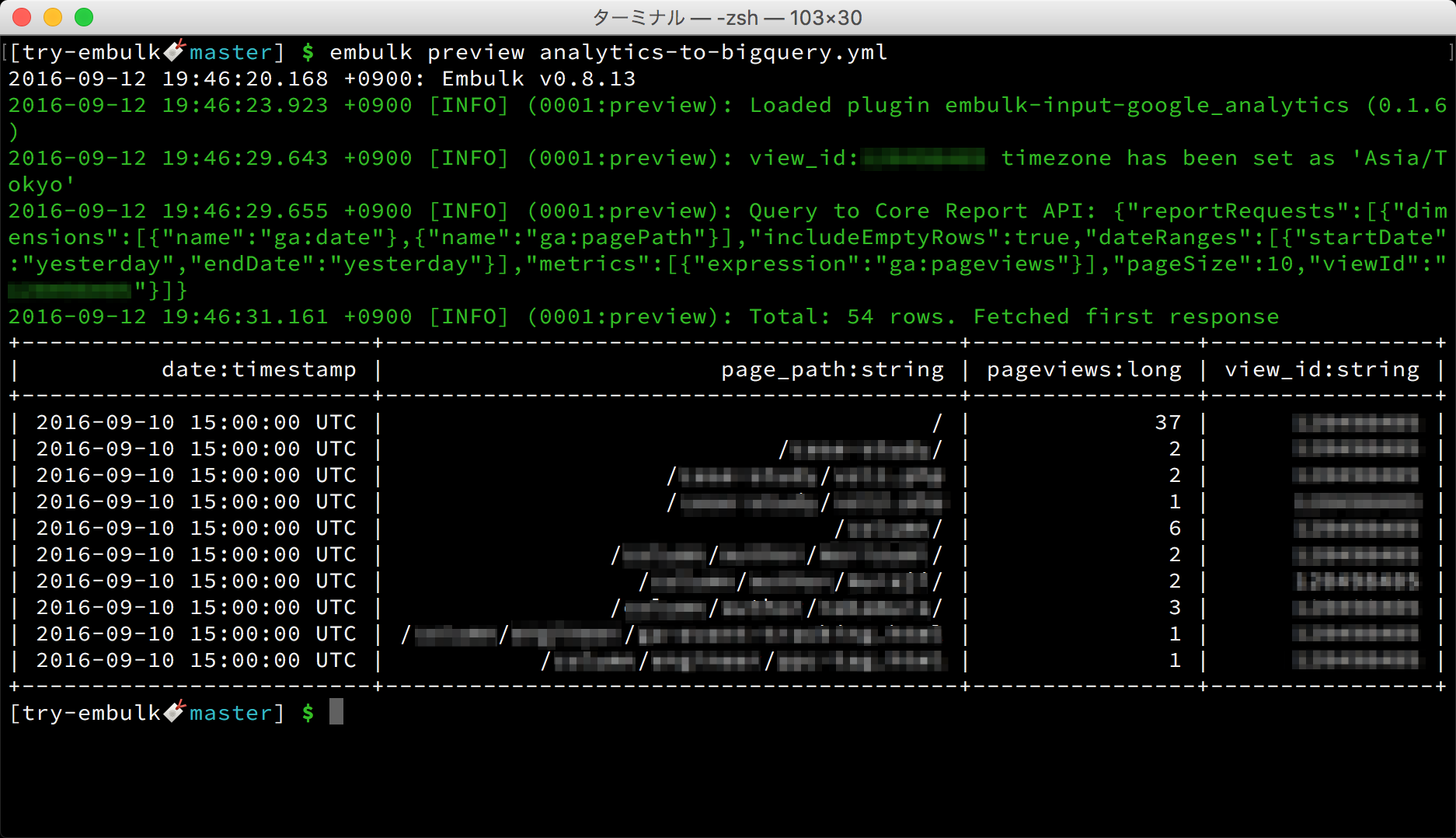
転送
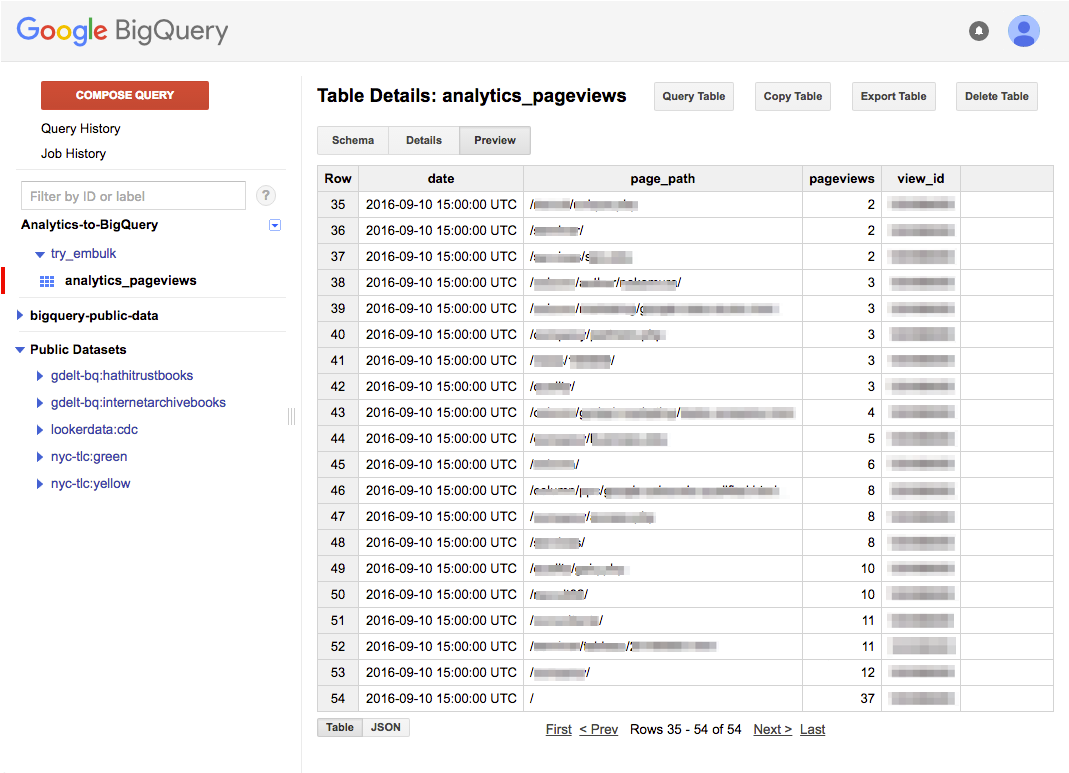
プレビューの内容に問題がなければ、ついにBigQueryへの転送です。
runサブコマンドを実行しましょう。
embulk run analytics-to-bigquery.yml
転送がエラーなく完了したのであれば、成果をBigQueryの管理画面で確認できます。
おわりに
以上、EmbulkのインストールからBigQueryへのデータ転送まで、一連の工程を紹介しました。活用のイメージを持っていただけたならば幸いです。
データ・ソリューションの発展が著しい今日において、その組み合わせのハンドリングは重要です。変化に対応する――プラグインと設定ファイルの変更でそれを実現するEmbulkには、大きな可能性を感じています。
なお弊社では、最新の知見を取り入れて、データ・プラットフォームの整備や分析のコンサルティングを提供しております。みなさんのビジネスにお力ぞえできれば幸いです。ご興味をお持ちいただけましたら、ぜひお気軽にご相談くださいませ。
お問い合わせフォーム






