
BigQueryでのデータ分析は多くの利点を提供しますが、時には予期せぬ高額な利用料金が発生することもあります。これは、大量のデータに対して複雑なクエリを実行した場合に特に顕著です。このような状況を避けるために、ジョブエクスプローラの活用が非常に有効です。CLIツールとは異なり、ジョブエクスプローラはより直感的でユーザーフレンドリーなインターフェースを提供します。
ジョブエクスプローラへのアクセス権限
前提として、BigQueryの管理リソースグラフの全データを表示するには、適切なIAMロールが必要です。特に、BigQueryリソース閲覧者(roles/bigquery.resourceViewer)のロールを持つことが重要です。このロールを持つユーザーは、組織内のBigQueryリソースの詳細情報を閲覧できます。必要に応じ組織の管理者にこのロールの付与を依頼してください。
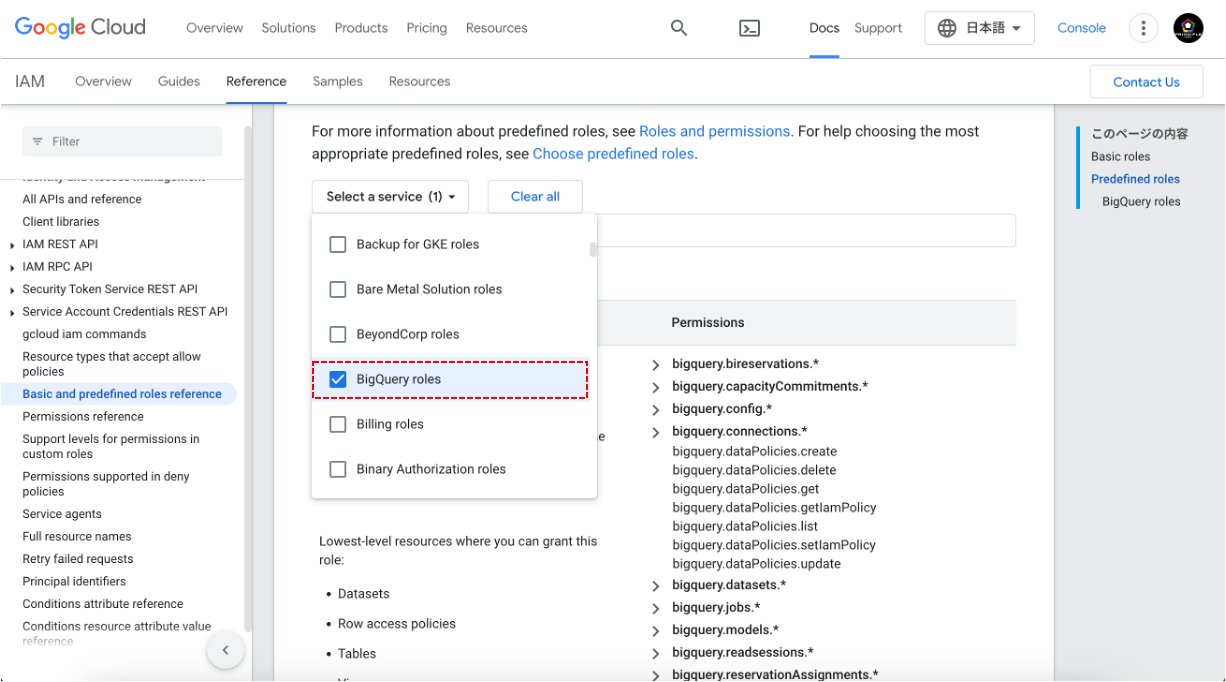
Google Cloudでは、さまざまな予め定義された役割が用意されており、それぞれが特定の権限(パーミッション)を持っています。これらの役割は、BigQueryを含む様々なGoogle Cloudサービスでのアクセス権限を管理するために使用されます。役割とそれに関連する権限の詳細は、以下のURLにアクセスし画面中段にあるBigQueryにチェックすることでロール一覧が確認できます。ご自身の状況や必要なロールを確認することもお勧めします。
ジョブエクスプローラの使い方
ジョブエスプローラはGoogle Cloud Consoleから簡単にアクセスできます。
以下はその基本的な使い方です:
- Google Cloud Consoleにログインします。
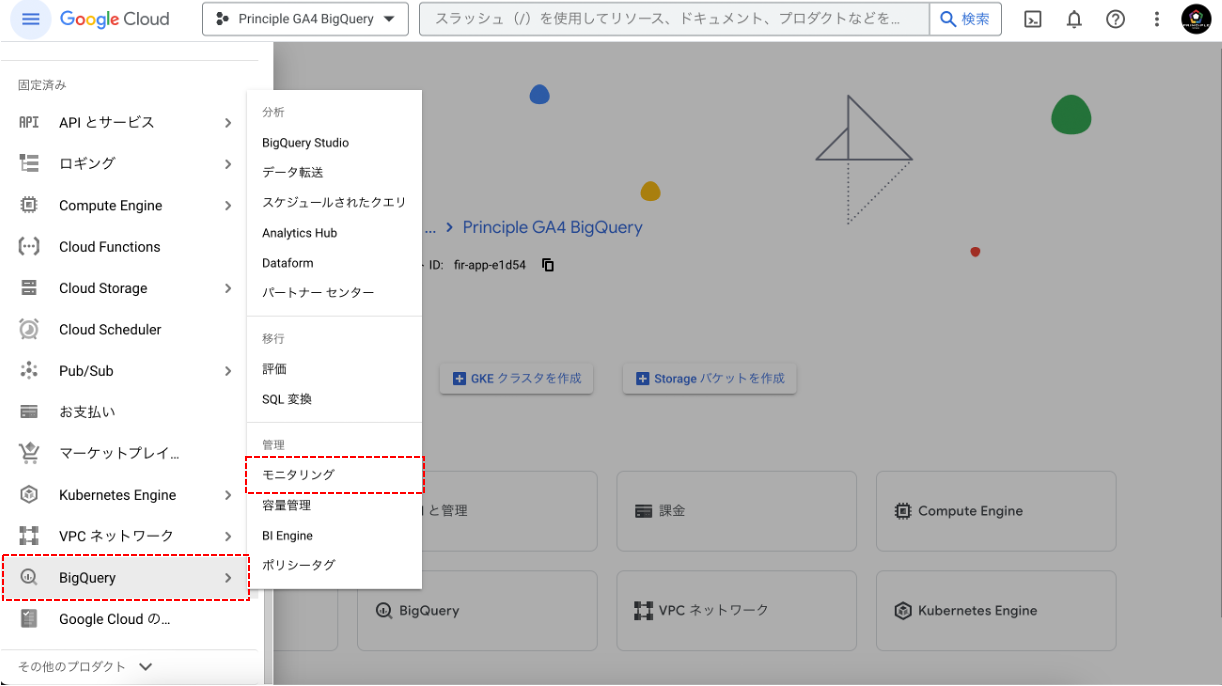
- ナビゲーションメニューから「BigQuery」をカーソルをおき表示メニューから、「モニタリング」にアクセスします。
- モニタリング画面から「ジョブエクスプローラ」タブを選択します。
ジョブエクスプローラの機能
- クエリの一覧表示:実行された全てのクエリの一覧を確認でき、どのクエリがどの程度の処理の大きさなのかをスロット時間やバイト数で示す一覧が表示されます。
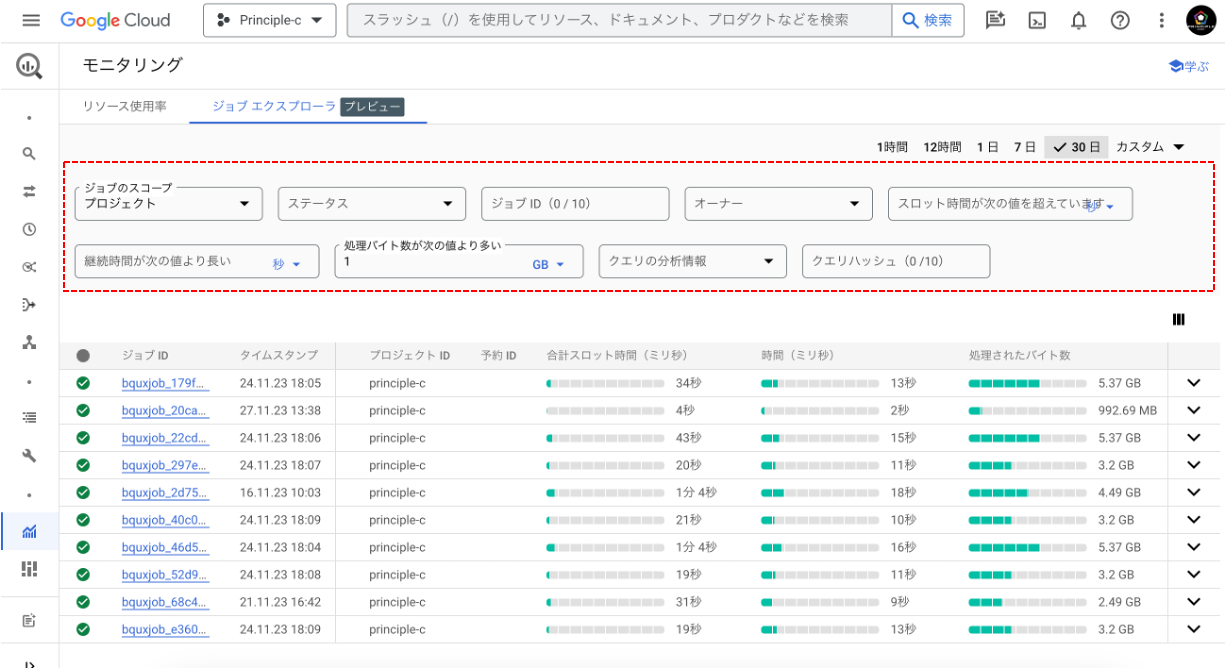
BigQueryにおけるスロット時間は、クエリ処理のためにクラウド側のリソース(CPU、メモリ)が使用される処理時間を指します。一方、バイト数はクエリによってスキャンされた総データ量を表します。これらのインジケータが高いジョブ(クエリ)は、その大きさ分の課金が発生しますので、コストを抑える効率的な運用や管理が求められます。数百Gバイトを超えるものや1TB以上のものは該当クエリと言えるでしょう。
ジョブエクスプローラでは、上の図に赤枠で示した部分を使って、対象範囲を指定し、ジョブ一覧をスロット時間やデータ量でフィルタすることが可能です。これにより、CLIでのコマンド実行の場合で生じていたジョブ一覧のJSON出力やその後のCSVへの整形処理といった一手間が省けます。結果として、コストが高くなっているスロークエリを比較的スムーズに特定することが可能となります。
- 活用の仕方として:スロークエリが特定できたら、今度は該当のジョブIDを上段のフィルター項目に貼り付け、一定期間内でどれだけ実行されているかを確認することができます。また、一覧上でジョブIDをクリックすることで、そのクエリの実行に関する詳細情報も確認できます。この中には実行時間、処理されたデータ量の他に、宛先となっているテーブルや、どこからのリクエストからの処理かを表現するラベルの値(Looker Studioの場合は、requestor:looker_studioと表記)が確認できます。
このようなジョブにおけるクエリ処理のプロファイリングを通じて、どう扱うべきなのかの整理に役立ててください。
コスト削減のためのヒント
BigQueryにおけるスロークエリは、それを最適化することでコストと実行時間を削減できる可能性があります。以下にてそのアプローチをご案内します。
- クエリ文のリファクタリング:
これは、クエリ文を改善して効率的にするプロセスです。
例えば、必要な列のみを選択する、適切な結合条件を使用する、効率の悪いサブクエリを改善するなどが含まれます。 - クエリ実行頻度の改善:
同じクエリを何度も実行する代わりに、結果を一時テーブルに保存し再利用する方法です。これにより、同じデータを何度も読み込む必要がなくなり、全体的なリソース使用量を減らすことができます。
- 中間テーブルの作成:
複雑なクエリの中間結果を保存するために中間テーブルを作成します。
これにより、後続のクエリで必要なデータのみをスキャンできるようになります。
また、BigQueryでのデータ管理を最適化するためのテクニックもあります。
- パーティション化:
パーティション化は、大きなテーブルを論理的に分割することを指します。
例えば、日付やIDなどの特定のキーに基づいてデータを分割することができます。
これにより、クエリは必要なパーティションのみをスキャンして処理するため、全体的な処理が速くなります。 - クラスタリング:
クラスタリングは、パーティション内のデータを特定の列(キー)に基づいて整理するプロセスです。これにより、クエリは関連するデータをより効率的に見つけることができ、スキャン量をさらに削減します。
- パーティションとクラスタリングの組み合わせは、特に大規模なデータセットにおいてクエリのパフォーマンスを大幅に改善することができます。これらのテクニックを適切に利用することで、必要なデータのみを効率的に処理し、BigQueryのコストと実行時間を削減することが可能になります。
まとめ
BigQueryのコスト管理は、クエリの実行状況を正確に把握し、必要な調整を行うことによって効果的に実施することが可能です。ジョブエクスプローラは、コスト管理を効率的に行うための非常に有用なツールとなり得ます。この記事が皆様のBigQueryのコスト管理に役立つことを願っています。
また、弊社ではデジタルマーケティング支援の一環として、BigQuery環境の構築をサポートしております。これには、扱うデータ構造の整理やその最適化も含まれます。ご興味のある方は、お気軽にご相談ください。







