
GA4がBigQueryへのデータエクスポートに対応している影響で、弊社のお客様でもBigQueryを新たに導入・活用するケースが増えてきました。
そこで今回は、弊社の見てきたお客様の運用とご提案した改善案の中から、BigQuery(※以下BQ)の運用費用を節約するベストプラクティスの1つをご紹介します。
よく見られる運用パターンと問題点
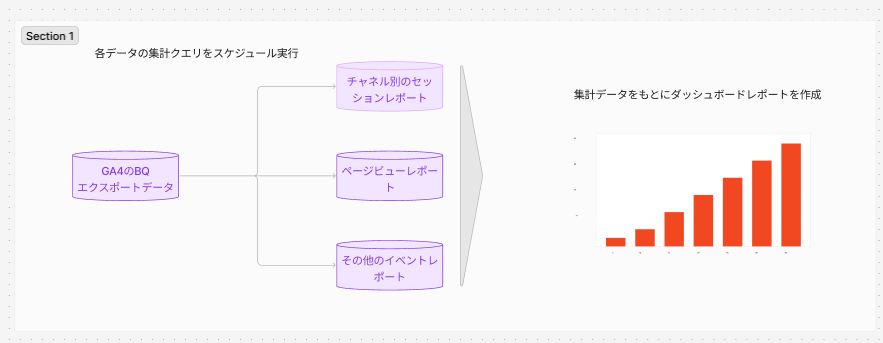
弊社で担当してきたお客様の中で最も多いのは、GA4のデータを利用してLSで可視化する際に「スケジュールされたクエリ」で処理を自動化しているパターンです。この運用方法にはどのような問題点があるのでしょうか?
同じ処理が複数回行われてる
上記のパターンだとGA4のRawデータを複数読み込んでおり、クエリ量が無駄になっています。これを紐解くために以下のサンプルクエリを見てみましょう。
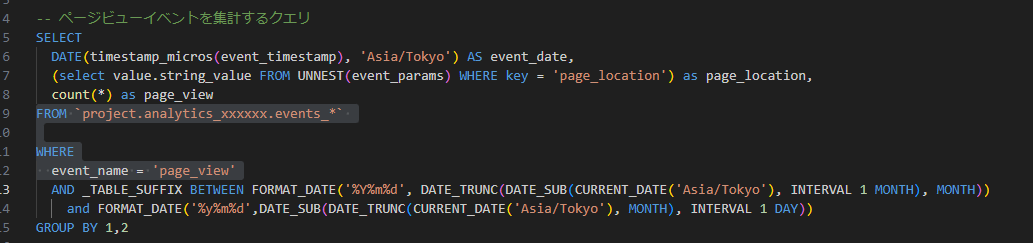
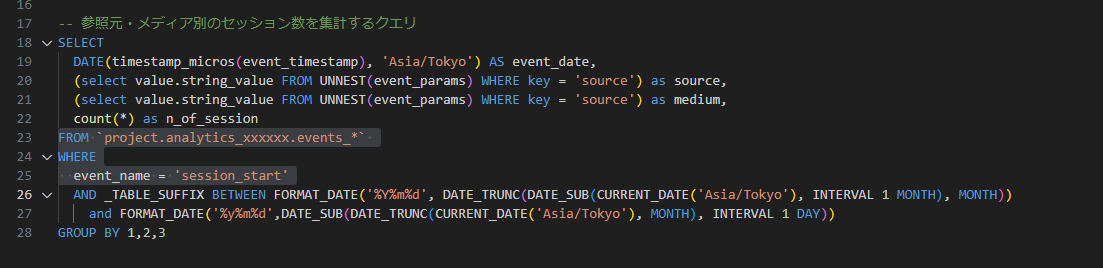
どちらのクエリもGA4のデータを読み込み集計対象のevent_nameをWHRER句で指定していますが、GA4のデータ上でevent_nameはパーテーションされていない(event_nameの指定によりスキャン量を削減できる設定がされていない)のでフルスキャンを実行していることになります。
GA4エクスポートデータは計測しているWEBサイトの規模間にもよりますが1か月分で数百GBに及ぶこともあります。ROWデータに対するスキャン量を削減することが、クエリ費用削減の第一歩となります。
改善策:クエリの共通要素をテーブルとして保存しよう
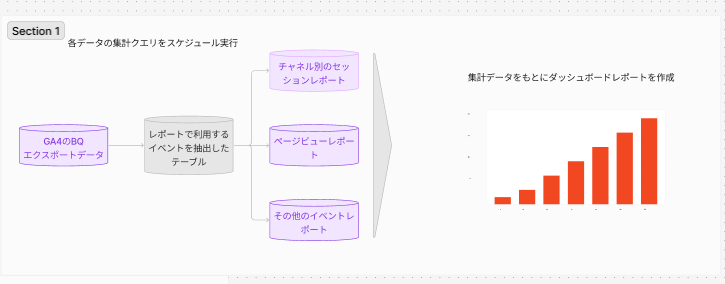
図のように、ROWデータの必要な要素をあらかじめテーブルとして保存することで、データフロー全体のクエリ量を削減することができます。保持するイベントの種類にもよりますが、この中間処理を行うだけでクエリ量を90%以上削減できる場合が多いです。
また先ほどの2つのクエリは以下のように書き換えることができます。
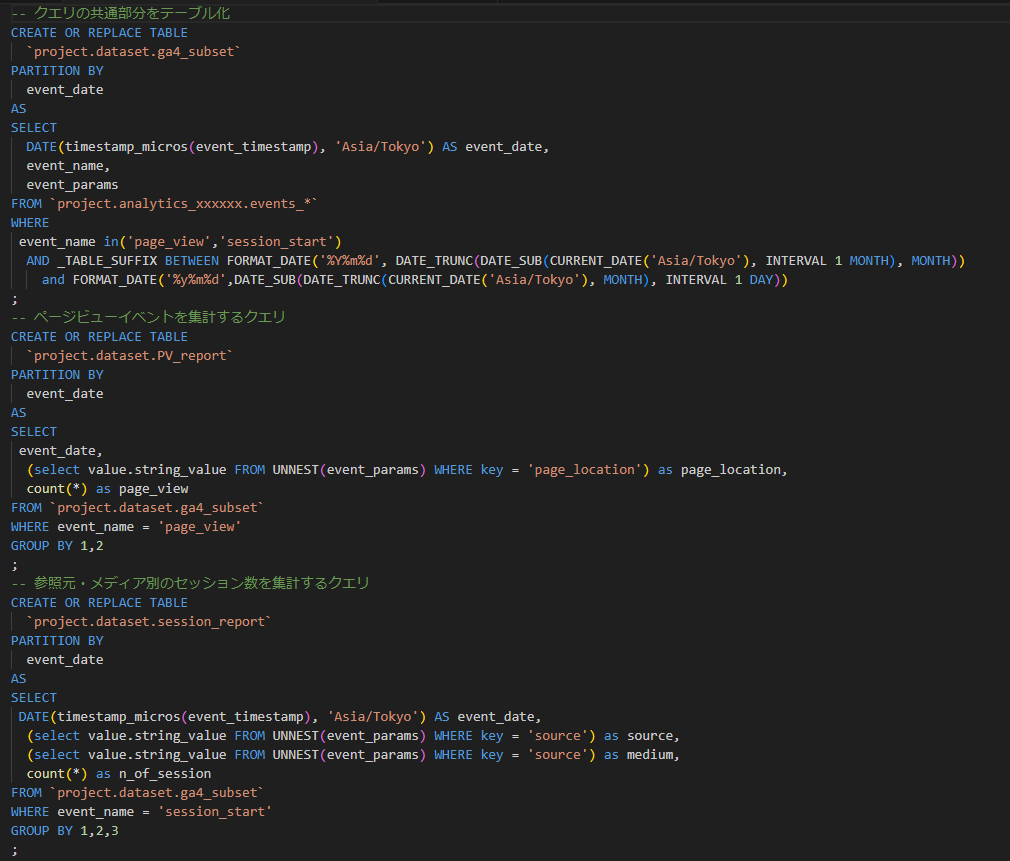
書き換えたクエリは従来の「スケジュールされたクエリ」機能に登録することもできるので、これまでの運用から比較的簡単に切り替えることができます。
さらに進んだ運用
しかし、実際には今回例に上げたような単純なクエリではなく、テーブルの結合などを含む複雑なクエリが運用されている場合が多いです。そのような場合は以下のようにさらに段階を分けたデータフローの構築をおすすめします。
データの処理によって層を分ける
以下の例では目的別にデータ処理の層を分けてデータフローを構築しています。
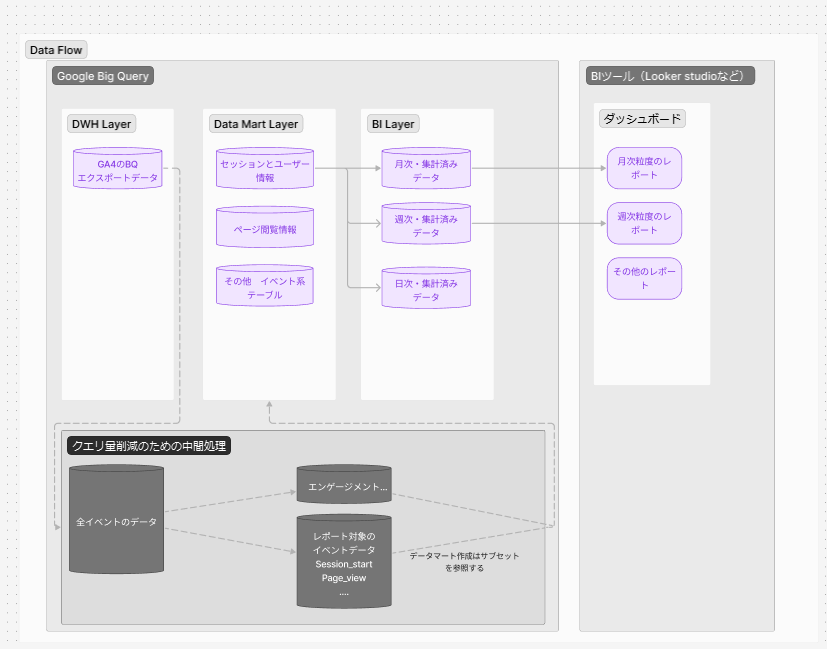
データマート層ではイベント別の主要パラメータをsession_id,user_presudo_id単位で保持しておき、BI層では各データマートを組み合わせてレポートに適した整形するといったコンセプトです。
こちらの運用方法ではデータ処理が構造化されるため、クエリ量の削減に加えて、メンテナンス性の向上などのメリットがある一方、クエリの実行制御などのエンジニアリングの知識が不可欠です。
まとめ
今回は、弊社の見てきたお客様とご提案した改善案の中から、BigQueryのクエリ費用を節約する方法についてお伝えしました。
ブログを読んでいる方の中にはすでに複数のダッシュボード作成のためにBQを利用している方もいらっしゃるのではないでしょうか?弊社では既存の環境の最適化に向けて現状調査から改善案のご提示、実装まで一気通貫してご支援をさせていただいております。ご興味を持たれた際はぜひ一度お問い合わせください!









