
先日弊社で「SEO無料60分オンライン相談会」という企画を限定3社様で実施しました。
その際にサーチコンソールの「クロールの統計情報」の見方・使い方があまり知られていないのではと思い至り、まとめた次第です。
専門書やブログでもこの辺の話はなかなか出てこないな、という一方、個人的には、クロールの統計情報は検索アナリティクス以上にサイトの健康状態を表すバロメーターと捉えていますので、読後としては、意味を理解してもっと使ってもらえるとうれしいな、と考えています。
各グラフの簡単な説明
弊社サイトデータのキャプチャをもとに説明します。
なおサーチコンソール(以下SC)のデータは、公式には取得から48時間後の反映とされ、かつ表示をGoogle本社のある太平洋時間に合わせているため、日本ではおよそ1.5日遅れで見ることができる、と考えてください。SCはGAのように時間の表示調整ができません。
https://support.google.com/analytics/answer/1308621?hl=ja&ref_topic=1308589
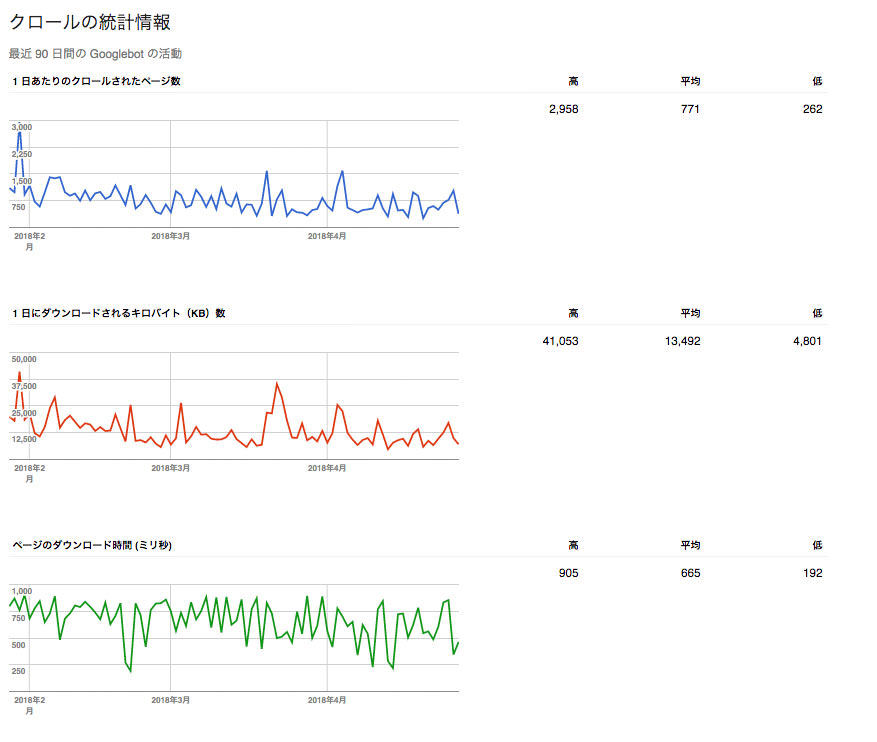
1日あたりのクロールされたページ数(青いグラフ)
文字通り、1日あたりGooglebotによりクロールされたページの数を指します。
お持ちのサイトについても、インデックスさせておきたいページとそうでないページがあると思います。前者は頻繁にクロールされてほしい一方、後者はクロールされる必要はないし、されたくないと言えるでしょう。インデックスさせたいページのみが毎日クロールされている状態が理想と言えますが、例えば、canonicalにより代表URLへ正規化を行なったページも、しばらくは(canonicalが理解されるまで)クロールされます。などなど、現実には両者の数は異なるものです。
1日にダウンロードされるキロバイト(KB)数(赤いグラフ)
Googlebotがページをクロールし、レンダリングするためにダウンロードしたファイルのKB数(1日あたり)、と捉えてください。
ページのダウンロード時間(ミリ秒)(緑のグラフ)
同じくGooglebotがダウンロードに必要とした時間と捉えてください。
共通項目
クロール統計情報も画面上、90日間のデータのみを見ることができます。「高」「平均」「低」はそれぞれ過去90日期間中の「最高値」「平均値」「最低値」です。
どのように見ればよいか?
まず、これらのグラフはどういう状態が良い、と言えるでしょうか。
「1日あたりのクロールされたページ数(以下『クロール数/日』)」では、前項でも記載した通り”インデックスさせたいページのみが毎日クロールされている状態”が理想です。しかし、実際には新しいコンテンツを追加するとクローラーも増える(※)ため、サイトの成長に伴って緩やかに増えているのが現実としては良い状態と言えます。
https://support.google.com/webmasters/answer/35253?hl=ja (※)
後に示すようにクロールが増える=100%問題ない、と言いきれないケースもありますが、緩やかな増加と表示回数・クリック数の増加が機を一にしている、とは以下のようなイメージです。
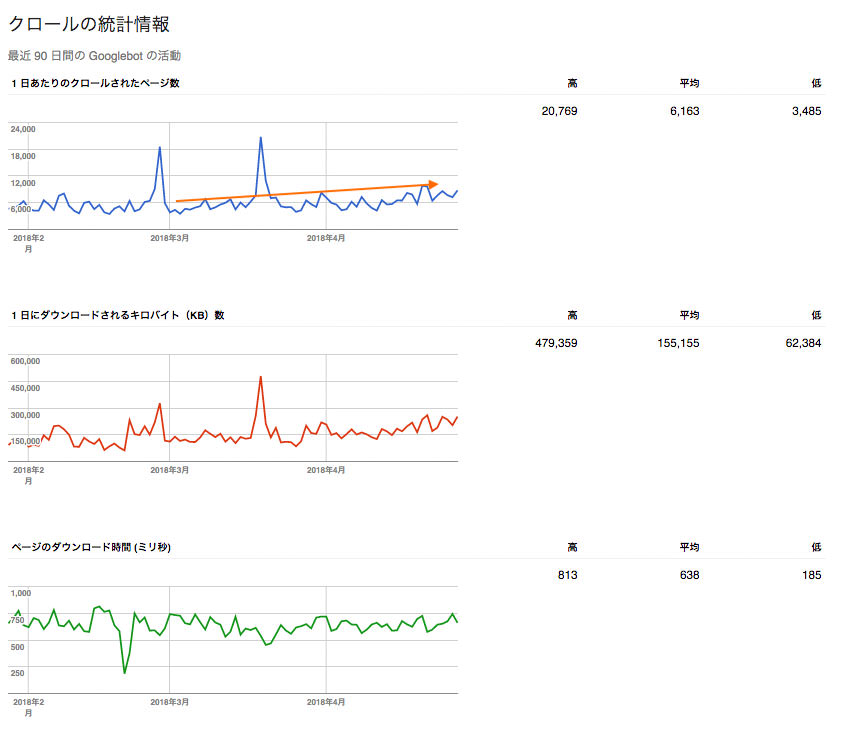
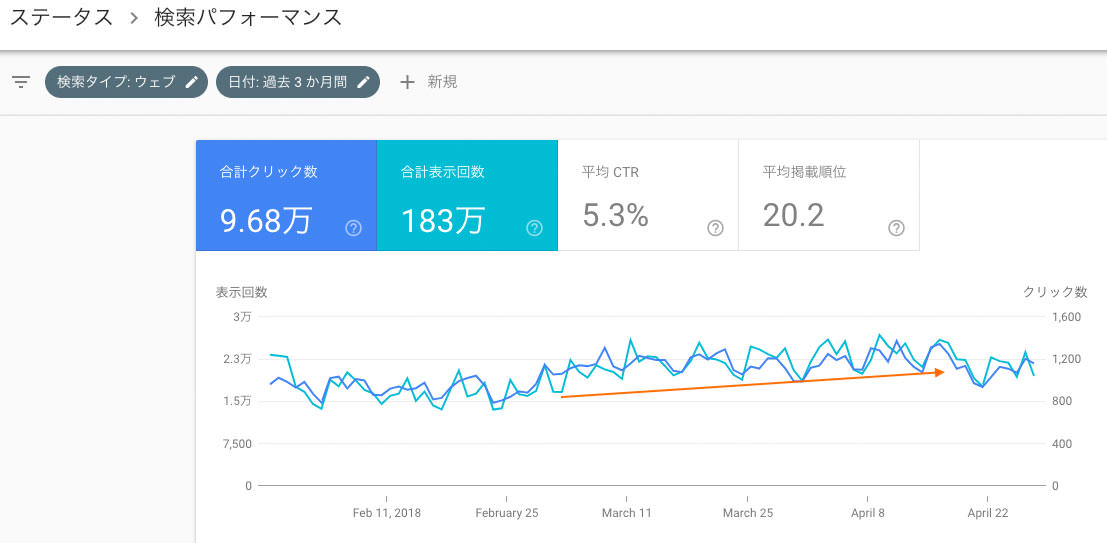
低品質でない、と認識されて頻度高く読まれるコンテンツが増えることで、インデックスが更新性も加味されて最新に保たれる、ということです。
補足(※)
Googlebotはサイトのページ数だけでなく品質も考慮してクロール数と頻度を調整します。いくらページ数が多くとも、クロール不要に見える低品質コンテンツがその大半を占めるようではよくありません。コンテンツが増えるとクローラーは来訪しますが、低品質であると認識されるといずれクロールを忌避しはじめます。
これはページ単位でなくドメイン単位、(ディレクトリ等の)テンプレート単位で判断されるものです。
「KB数」「DL時間」については、SEOの面で良いサイトという前提であれば、平衡的である状態が良いと言えます。というのも、DLされるファイル(cssやimgファイルなど)のKB数やDL時間はサイトに何らかの改修を加えない限りあまり変わらないものと言えるからです。
他方、グラフに意図しない大きな変化があった際には改修のタイミングと合わせてSEO観点での見落としを疑ってみるべきです。たとえば、改修の際に穴が空き(=クロール不要なファイル/ディレクトリのrobots.txtなどによるブロックが外れるイメージ)、低品質コンテンツやクロール不要ファイルにクローラーが押し寄せ、情報量が少ないファイルへの大量アクセスを疑います。
「クロール数/日」についても、一時的な増加の後に逓減する場合は、改修を行なったので来訪されたものの低品質コンテンツが目立つので全体のクロール数/頻度を下げられた、と疑えます。
このように、クローラーの統計情報への接し方は、平時の「変化がないな」「なんならクロール数/日が上昇基調だな」という観測は元より、SEOを含む改修施策を行なった場合に「意図しない/不審な変化がないかどうか」を確かめる方により重きが置かれると言えます。
理想のクロールページ数とは、以下の内容から決まると言えます。
- 詳細ページ(商品・求人・案件・記事等)の数
- 一覧ページ(絞り込み・検索結果)ページの数
- その他、個別コンテンツページ数
- 上記それぞれの更新頻度
上記の要素を踏まえて、クロールの過不足を判断します。
- ページ数、更新頻度に対して極端に少ない
→インデクスされるべきページが適切に認識されていない - ページ数、更新頻度に対して極端に多い
→無駄なURLのクロールが発生している。
上記のような時は、SEOで上手く評価されていないケースが多いです。
ケース
クローラー統計情報は、お示しした通りサイト統一的な基準数値がありません。サイトによって適正値が異なるもので、グラフの変化についても原因が幾通りにも推測され、解釈を必要とします。ありがちなミスとクローラー統計情報のデータ変動はよく連関しますので、いくつかのケースをご紹介します。
ケース1 不意のrobots.txt
robot.txtで不意に特定のファイル/ディレクトリのパスをブロックしてしまうと、クローラーは行き先をなくして、サイトのサイズを過少に判断してクローラーの数を減らしてしまいます。
レポート上の事象としては「クローラー数/日」がみるみる減ってしまいます。
初歩的な誤りですが、例えば開発環境から本番への適用にあたりCMS側で自動的にブロックしたままにすると、このような事態が起こります。また、robots.txt への正規表現の記述の誤りにより、このような自体が起こることもありますので、SCのrobots.txtテストツールで定期的にチェックすることが有効です。
ケース2 不要なURLのクロール
サイト改修後のcanonicalの不意な除去や、放置された重複コンテンツが見つかることで、急にクロールが増加することもあります。この事態は一時的に見た目は「クローラー数/日」のグラフは増加しますが、その後平均的に右肩下がりを辿ることになります。
急に読めるURLが増えるもので一時的にクローラーが増えますが、低品質コンテンツを認識され、あるいは重複コンテンツをインデックスされてしまい、結果としてドメイン全体としての評価を落としてしまうことになります。
クロール数は先に示した通り、新しいコンテンツの追加に伴って増加します。他方、Googlebotでないクローラーの偽装来訪、原因不明の増加、またXMLサイトマップを入れ替えるなどで意図的にクローラーの来訪を呼びかけることもできます(確実に来訪されるとは限らない)。
このように、特に「クローラー数/日」のグラフは急増することが往々にありますが、その後の経過と合わせて慎重に見極める必要があります。こういったことが起こった際は、同時にクロールエラー/ソフト404 等の数字が上がっていないが確認し、原因を特定してください。新SCのインデックスカバレッジレポートで、想定外に認識されているURLが無いかを確認するのも有効です。
ケース3 画像だけのページが急に読まれる
情報量の少ないページが読まれ出すと、KB数やDL時間が急に低空飛行を始めます。
たとえばECで、商品詳細ページの画像をクリックした場合、ページとは別に画像だけのURLを充てているとすると、このケースを疑ってください。
画像だけのURLが存在すること自体でなく、低品質と評価されがちであることが問題と言えます。これらのグラフの低空飛行ののちにクロール数/日が逓減しはじめたら、クロールをブロックするなどの対策を講じてください。
事例
クロールの統計情報を問題の検証に役立てることもできます。
以下はメディアサイトで、画像の重さと読み込み速度の遅さを問題として挙げ、抜本的な画像の圧縮を行なった際の事例です。
クローラーはページの途中で離脱することもあります。今回で言えば、画像が重すぎ、読み込みに困難を感じて離脱されていたことが想定されました。結果クローラーは該当のディレクトリを忌避するようになり、インデックスが新鮮に保たれなくなっていました。
画像圧縮によりクローラーに画像を読みやすくすることで改善を実施し、結果としてクローラーがページに再び来訪するようになり、ページの情報をよく理解されることとなりました。
経緯を追ったのが以下のグラフです。
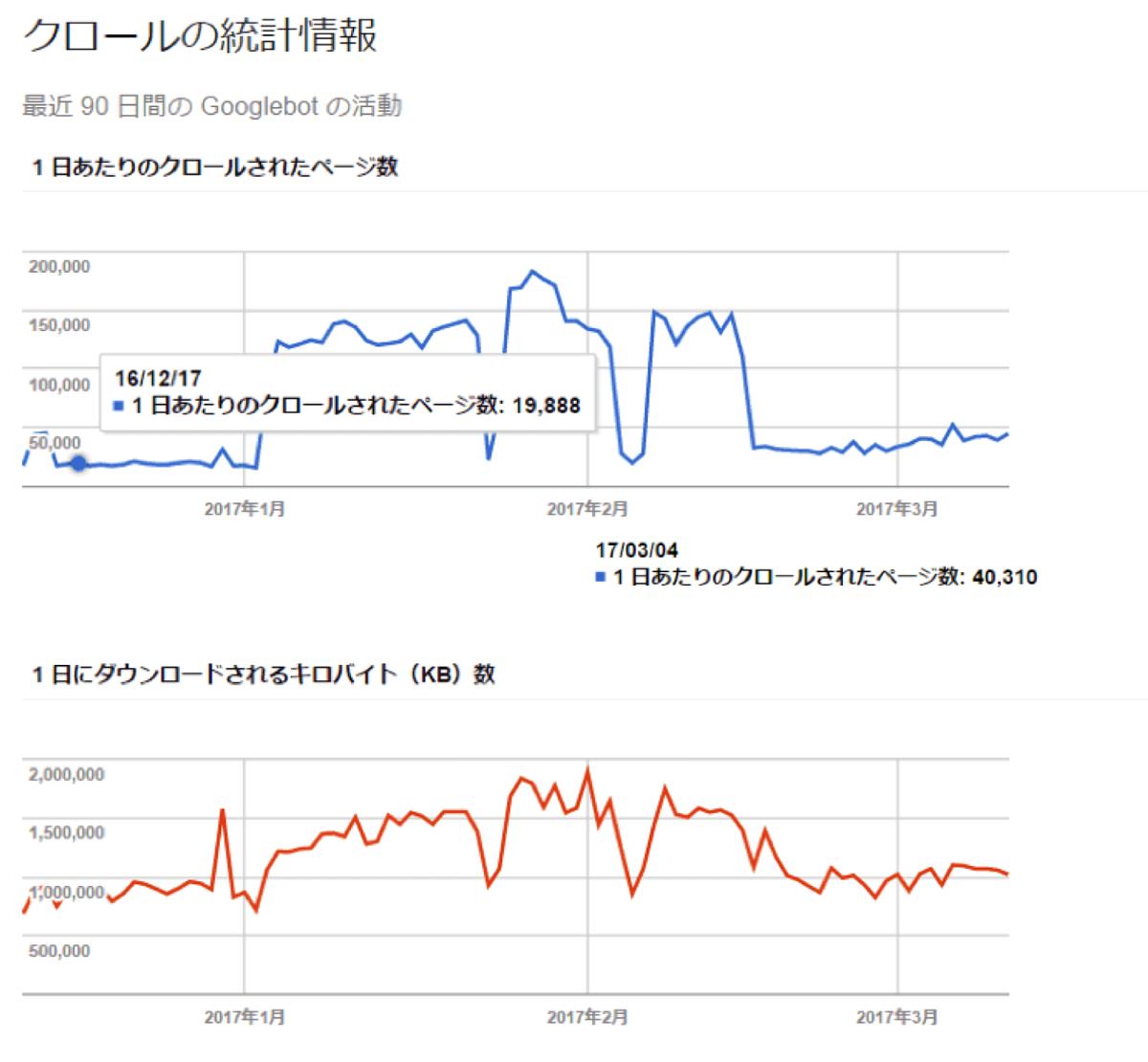
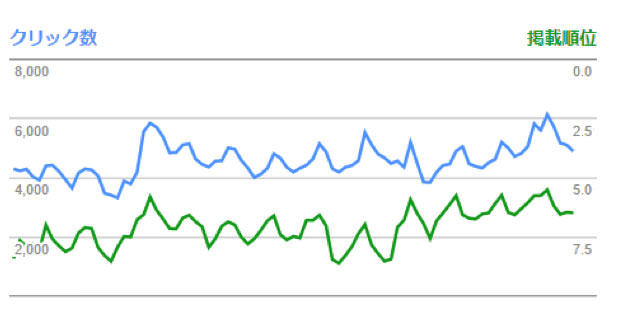
3ヶ月でクリック数が1.4倍に増加、順位と改善しました。このクリック増加とKB数の改善が機を一にしているため、このサイトは画像の重さ/速度は伸び代の見込める課題であると考えられ、画像の使用に対して圧縮を徹底するルールが設計されました。
まとめ
クロールの統計情報は現在はAPIに組み込まれておらず、SC上では90日間で情報が消えてしまいます。ベータ版にもいまのところ採用されておらず(今後は検索アナリティクスのように過去長く見られることとAPIを期待)、クロール数の推移は定点でキャプチャするなりで追いかけるしか蓄積しておく術がありません。
一方、「なぜ上がったのか」「下がったのか」の原因究明には非常に役立つと言えますので、これからは施策の実施とセットでチェックいただくことでよりPDCAが回ると思います。おすすめです。
参考にした情報
https://support.google.com/webmasters/answer/35253?hl=ja
https://support.google.com/webmasters/answer/80553
https://moz.com/blog/an-updated-guide-to-google-webmaster-tools






