
BigQueryとGA4を連携させることにより、GA4データの活用を最大化することができます。
この記事では、GA4データをBigQueryに連携する方法から連携後の活用方法、ダッシュボードによるモニタリングまで、具体的な事例を交え解説します。
BigQueryの概要
BigQueryはGoogle Cloudのプロダクトのひとつで、ビッグデータ分析に特化したデータウェアハウスです。
高いスケーラビリティ(拡張性)とパフォーマンスを誇り、ペタバイト(1000テラバイト相当)級の膨大なデータを短時間で処理できます。これにより、自社に蓄積しているさまざまなデータソースからデータを集約し、加工・分析することで、ビジネス成長における重要な意思決定をサポートします。
また、サーバーレスなためインフラ管理は不要で、ユーザーは分析に集中できます。SQLクエリを使用して簡単に操作でき、リアルタイムのデータ処理や機械学習との連携も可能です。
GA4データをBigQueryにエクスポートするメリット
GA4データをBigQueryにエクスポートすると、以下のようなメリットがあります。
- GA4データを長期間保存できる
- SQLを使ってGA4生データでの分析ができる
- SQLでセグメントを再現できる
- GA4以外のデータとの統合分析ができる
GA4データを長期間保存できる
GA4データをBigQueryにエクスポートしておくことで、データを長期間保存しておくことができます。
GA4探索レポートでは最大14ヶ月分のデータしか参照することができませんが、BigQueryにエクスポートすると14ヶ月以上の保存が可能です。これにより分析したい指標の年別推移や、過去データとの比較分析が実現できます。
SQLを使ってGA4生データでの分析ができる
BigQueryエクスポートでは、GA4の生データがエクスポートされます。
GA4の標準レポートや探索レポートはサンプリングやしきい値が適用されるケースがありますが、BigQueryエクスポートデータでは生データを扱うことができるため、実際のデータに基づいた分析が可能です。
SQLでセグメントを再現できる
Looker StudioでGA4データを可視化する際、GA4標準コネクタを利用するとセグメントを適用できません。BigQueryエクスポートデータを利用すると、SQLでGA4データを自由に加工できるため、セグメントを再現したテーブルを構築できます。
構築したテーブルをLooker StudioのBigQueryコネクタで接続し、セグメントデータの可視化もできます。
GA4以外のデータとの統合分析ができる
CRMデータやSFAデータなど、自社が保有しているデータをBigQueryに連携し、共通のIDをキーにGA4データと統合することで、複数チャネルを跨いたデータ分析を行うことができます。
複数データでの統合分析により、GA4データだけでは見つけられない課題の発見や、新たなインサイトを導き出すことができます。
カギとなる共通のIDについては、ブログ記事「実プロジェクトから気付いたデータ統合実行にありがちなつまずきポイント」をご覧ください。
GA4データをBigQueryにエクスポートする手順
手順1. BigQueryプロジェクトを作成
まず、Google Cloud 公式サイトへアクセスし、「BigQueryの無料トライアル」をクリックします。
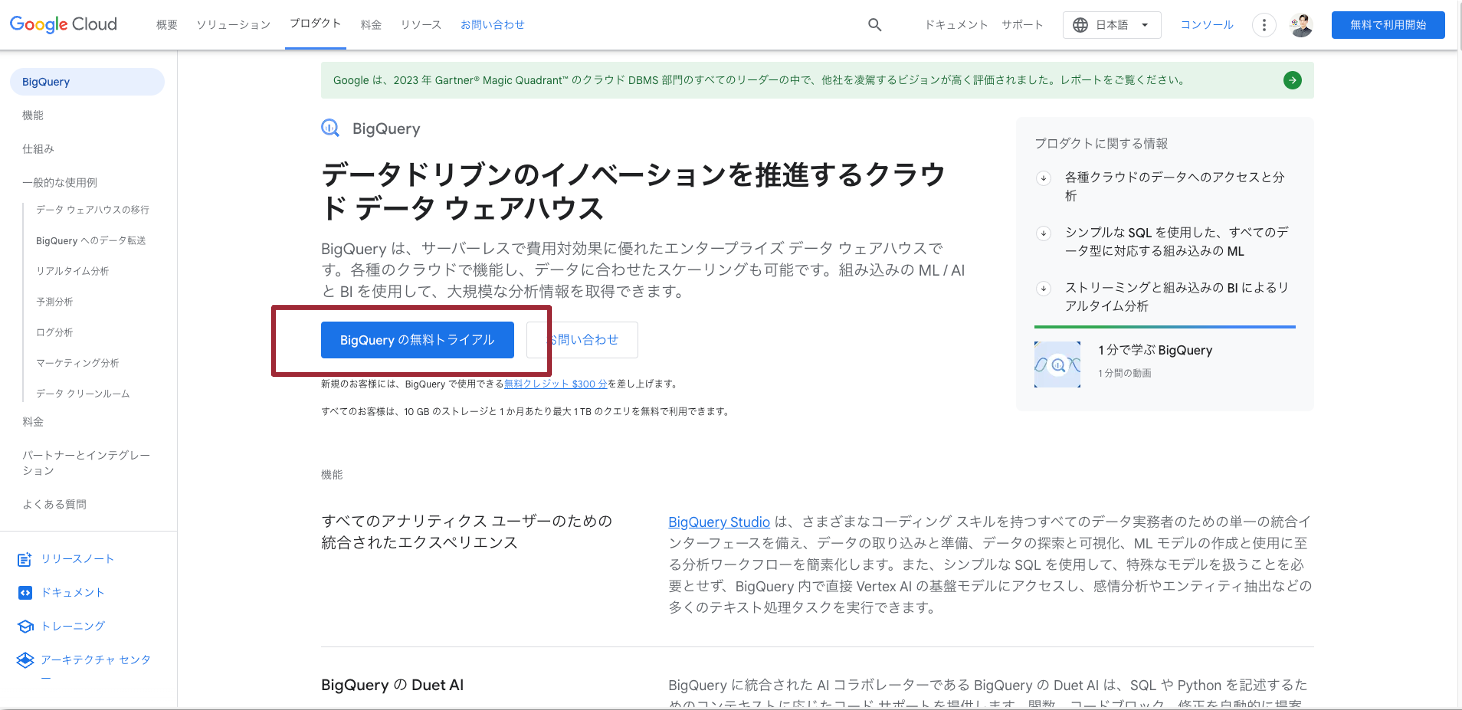
アカウント情報を入力します。

お支払情報を入力します。無償版ではデータの保存期間に制約があるため、支払い設定をし、有償版を利用することを推奨します。

お支払い情報の入力が完了すると、Google Cloudへの登録は完了です。
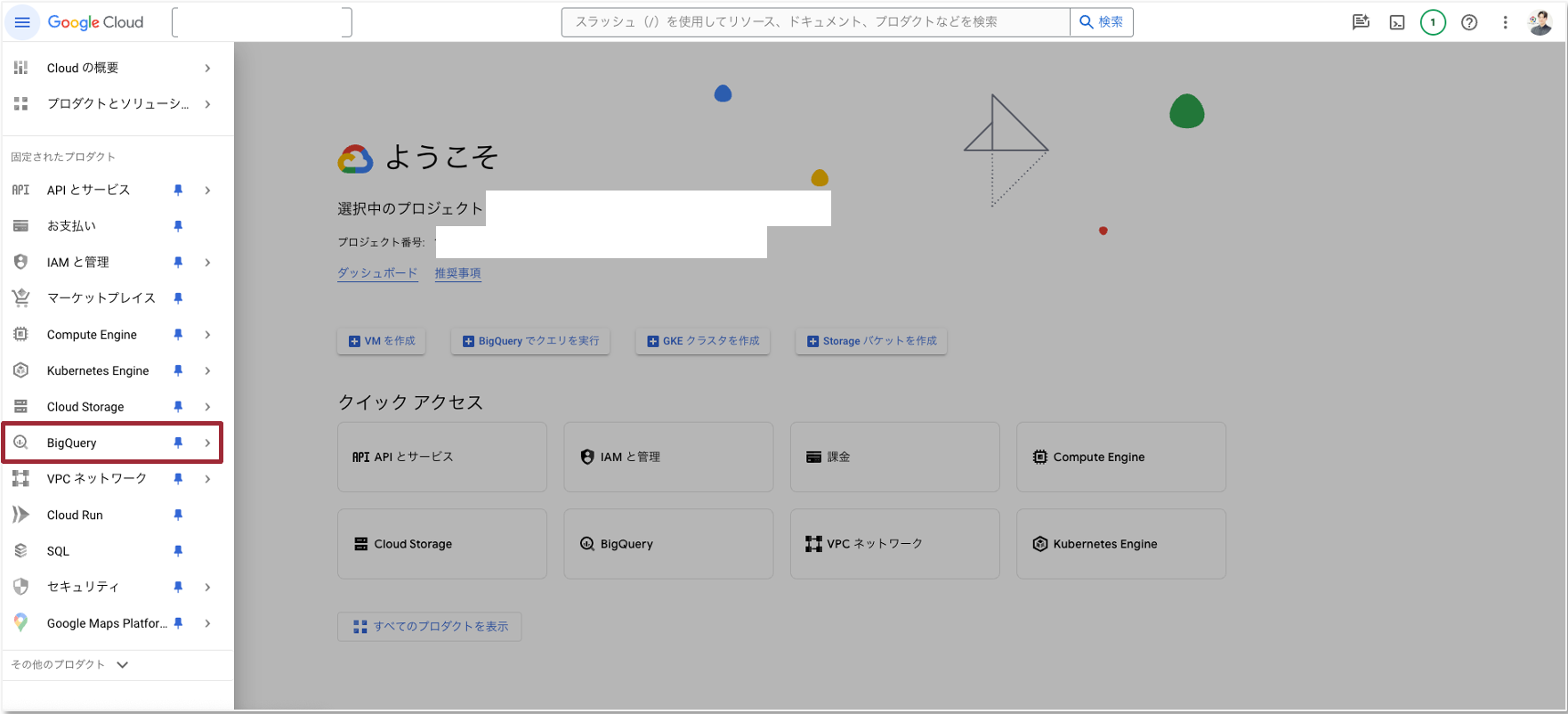
画面左上のハンバーガーメニューより、「BigQuery」を選択します。
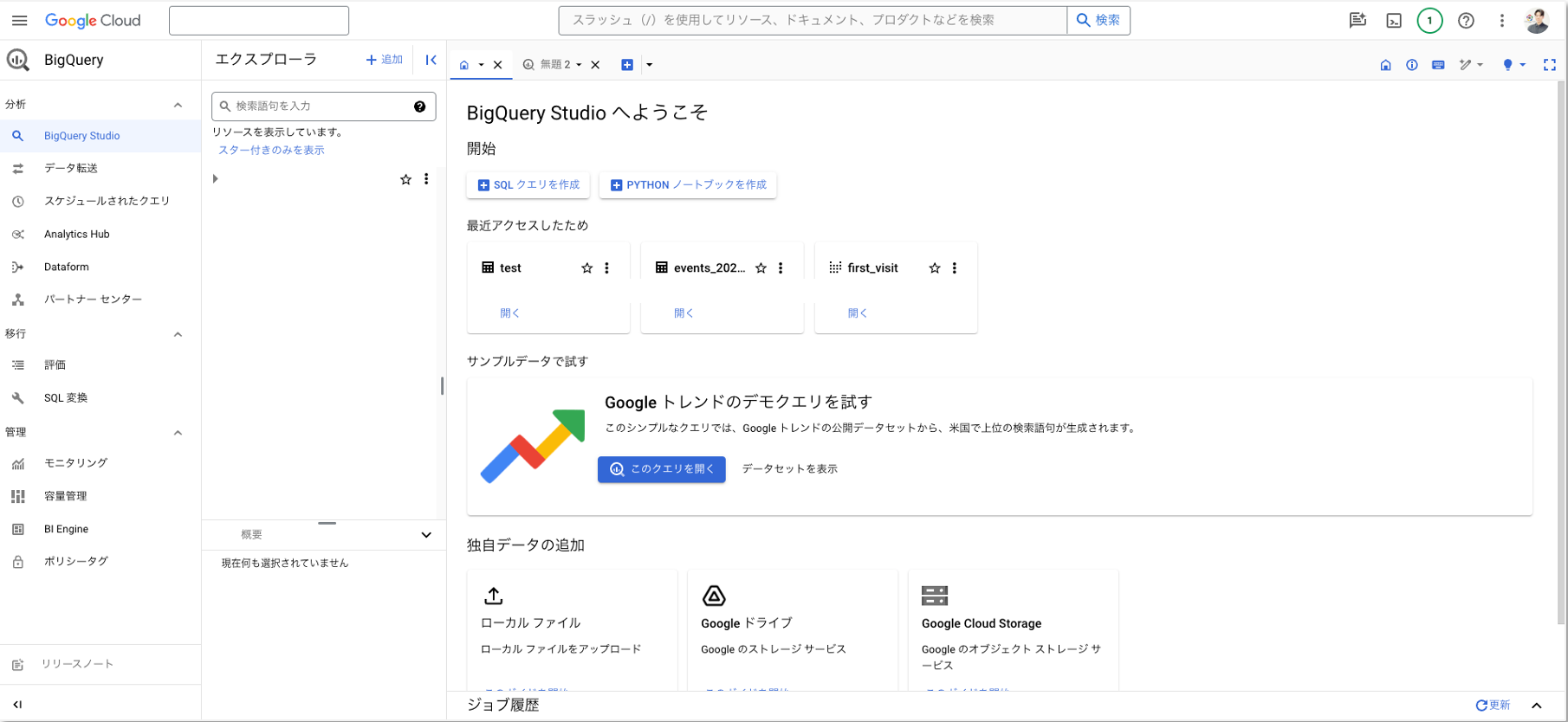
BigQueryのコンソール画面が表示されます。
手順2. APIを有効化
Google Cloudコンソール画面左上のハンバーガーメニューより、「APIとサービス」へ移動し「BigQuery API」を選択します。APIが有効化されていない場合は有効化します。
手順3. GA4でエクスポート設定
GA4の管理画面を開き、「サービス間のリンク設定」から「BigQueryのリンク設定」を選択します。
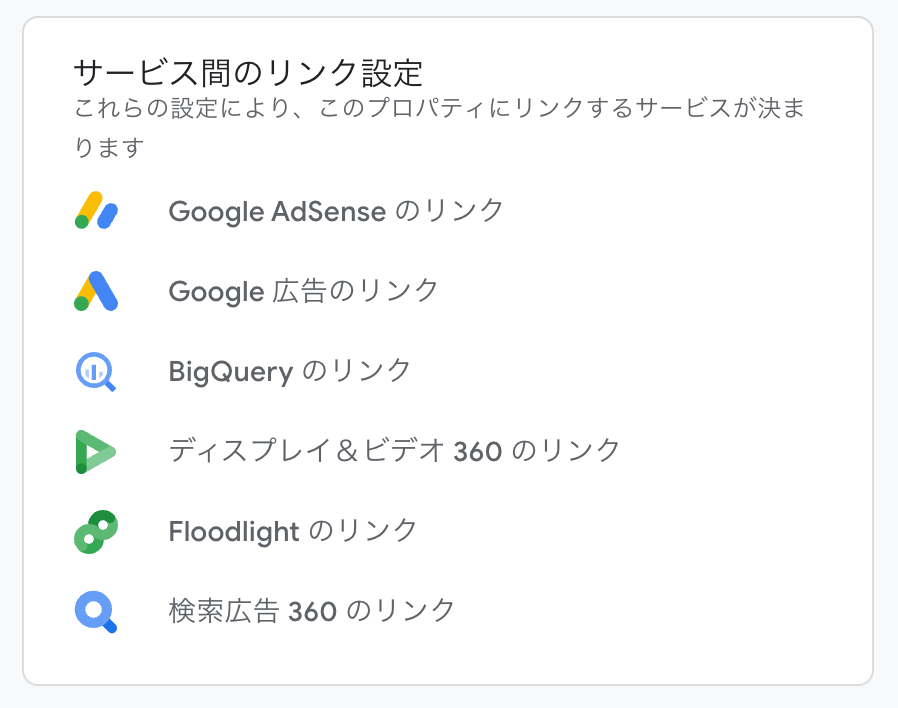
先ほど作成したBigQueryプロジェクトを選択し、データロケーションとエクスポート頻度を設定します。
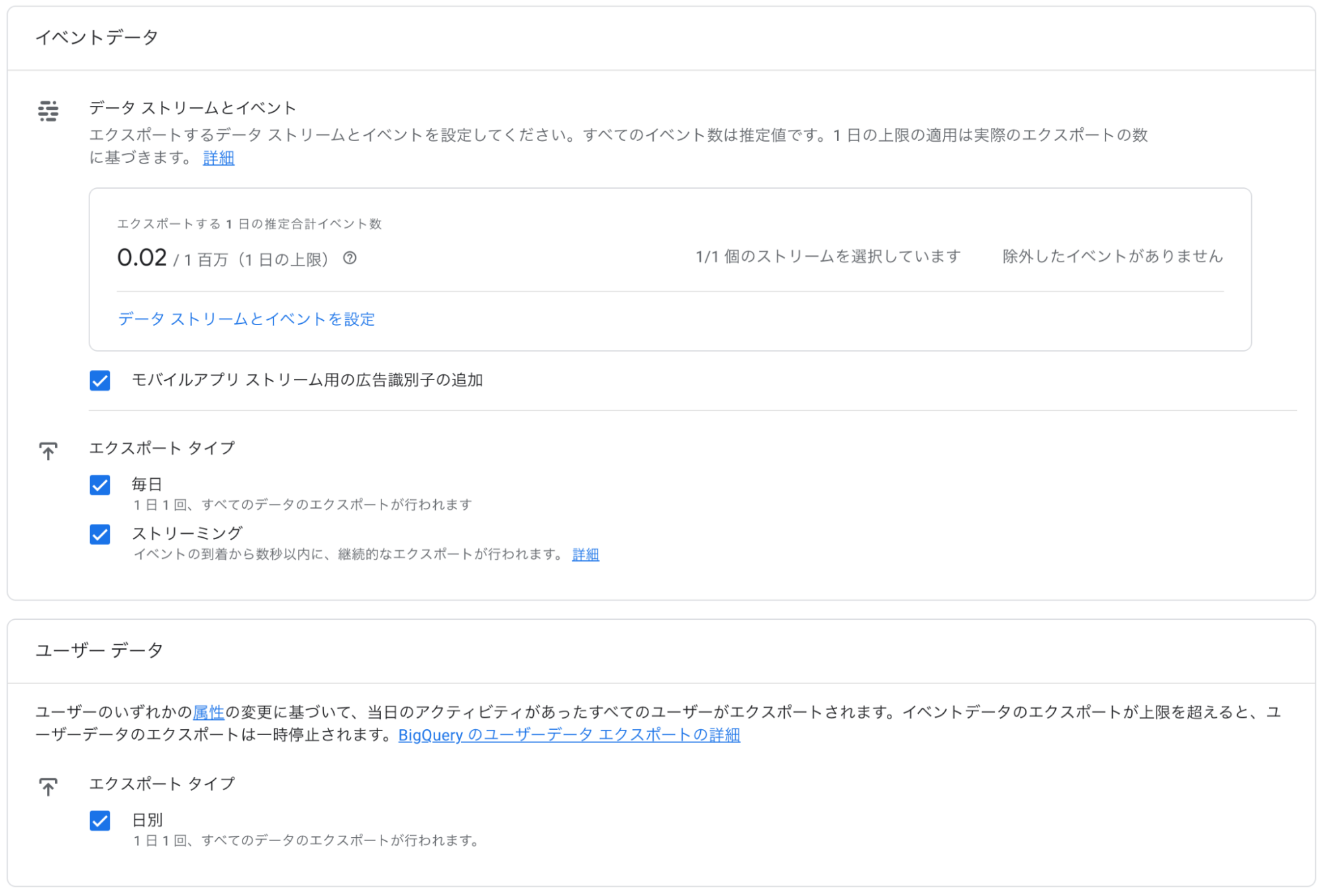
最後に設定内容を確認して、「送信」を押下します。
エクスポートされたデータを確認する方法
GA4の管理画面で設定すると、24時間以内にBigQueryでデータが確認できるようになります。
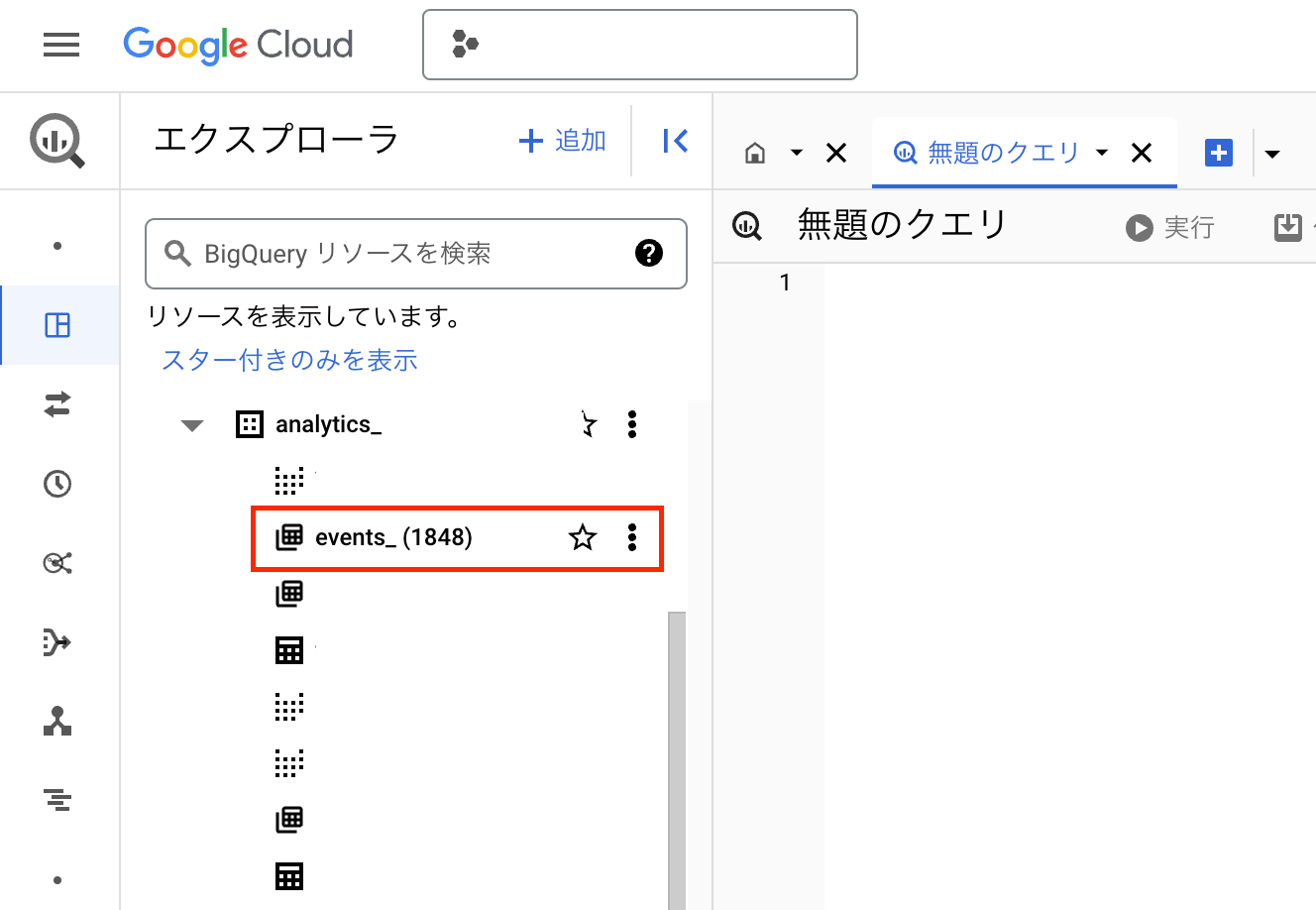
エクスポートされたデータを確認するには、BigQueryの画面を開き、対象のプロジェクトを選択します。プロジェクトの中に「analytics_〇〇」というデータセットが作成され、その配下に日付で分割されたGA4テーブルが生成されます。
設定時におさえておくべきポイント
エクスポート設定時におさえておくべきポイントは以下の5点です。
- エクスポート条件を適切に設定する
- バックフィル機能はなし!連携するなら早めの判断が必要
- プロパティの設定によってはユーザーIDのエクスポートが行われない
- BigQueryのエクスポート制限オーバー!どう対策する?
- BigQueryに格納したデータ分析をするならどのような権限を付与すべき?
詳しくはブログ記事「GA4とBigQueryを連携する際におさえておくべきポイント5選」でご紹介しています。ぜひご一読ください。
BigQueryエクスポートデータ分析のポイント
BigQueryエクスポートの分析において、抑えておくべきポイントをご紹介します。
ポイント1. GA4生データは加工が必要
BigQueryにエクスポートされたGA4生データは、「ネスト構造」になっています。「ネスト構造」とは、1つのレコードの中に、複数のレコードが入れ子になって格納されている構造のことを意味します。
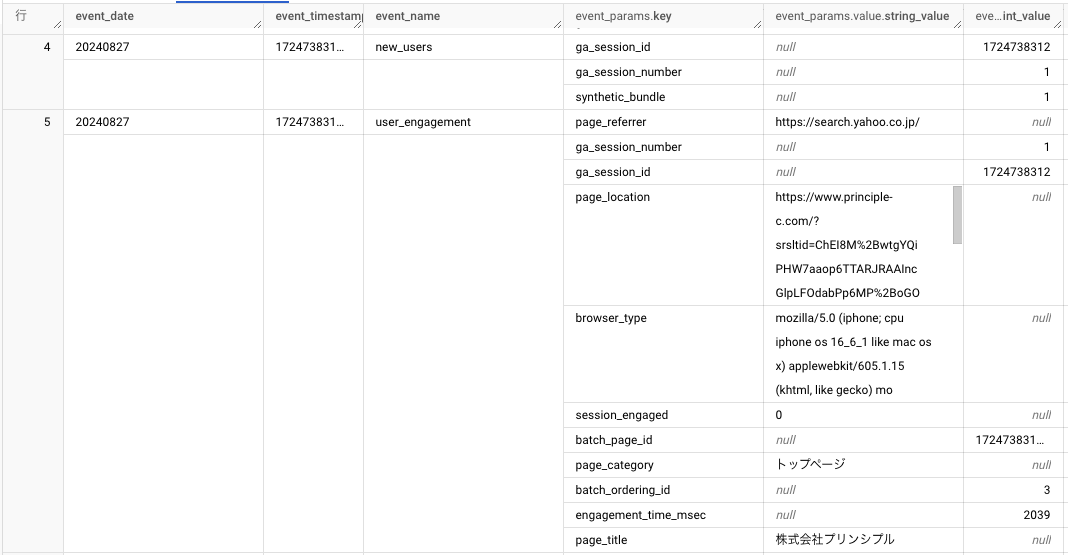
そのため、入れ子になっているデータを参照したい場合は、SQLの「UNNEST(アンネスト)」と呼ばれる構文で入れ子の解除を行う必要があります。
UNNESTするためには、たとえば、ページURL別のPV数を集計する場合、以下のように記述します。
SELECT
(SELECT value.string_value FROM UNNEST(event_params) WHERE KEY = ‘page_location’) AS page_location
,COUNT(*) AS pv
FROM
table_name
GROUP BY 1
上記SQLの「UNNEST」が入れ子の解除を行う処理です。これにより、イベントパラメータとして格納されているページURLの情報を抽出できます。
ポイント2. よく使う指標の集計方法
よく使う指標である「新規ユーザー数・既存ユーザー数」「エンゲージメントセッション数」は下記のように集計します。
▼新規ユーザー数と既存ユーザー数の集計方法
WITH
base AS (
SELECT
DISTINCT
user_pseudo_id
,(SELECT value.int_value FROM unnest(event_params) WHERE KEY = 'ga_session_number') AS ga_session_number
FROM
`project_name.dataset_name.events_20240101`
WHERE
event_name IN ('session_start')
)
SELECT
count(DISTINCT CASE WHEN ga_session_number = 1 THEN user_pseudo_id ELSE NULL END) AS new_users
,count(DISTINCT CASE WHEN ga_session_number > 1 THEN user_pseudo_id ELSE NULL END) AS returning_users
FROM
base
▼エンゲージメントセッション数の集計方法
WITH
base AS (
SELECT
user_pseudo_id
,(SELECT value.int_value FROM UNNEST(event_params) WHERE KEY = 'ga_session_id') AS ga_session_id
,MAX((SELECT value.string_value FROM UNNEST(event_params) WHERE KEY = 'session_engaged')) AS session_engaged
FROM
`project_name.dataset_name.events_20240101`
GROUP BY 1,2
)
SELECT
COUNT(DISTINCT CONCAT(user_pseudo_id,'-',ga_session_id)) AS sessions
,COUNT(DISTINCT CASE WHEN session_engaged = '1' THEN CONCAT(user_pseudo_id,'-',ga_session_id) ELSE NULL END) AS engaged_sessions
FROM
base
ポイント3. GA4管理画面とBigQueryエクスポートデータで値が異なる理由
GA4管理画面のデータとBigQueryエクスポートデータの集計データとで、数値差異が生じます。その理由について解説します。
GA4ではデータを素早く表示するために、データの全量を緻密に集計するのではなく、ある一定範囲のデータをサンプリングし集計しています。つまり、表示されるデータには推定値が含まれます。一方で、BigQueryエクスポートデータは推定値を含まないGA4の生データであり、SQLを用いて緻密な集計を行うことができます。
このようなデータ集計方法の違いにより、GA4管理画面のデータとBigQueryエクスポートデータの集計データでは、数値差異が生じることがあります。しかしながらあまりにも大きな数値差異が生じるケースは少なく、弊社ではGA4管理画面とBigQueryを使い分けながら、ご支援させていただいております。
BigQueryコストパフォーマンス最適化のコツ
BigQueryを利用すると、利用状況に応じて料金が発生します。(※一部無料枠あり)
組織で利用する際、コストを可能な限り小さくすることが求められることがあります。ここではBigQueryの料金体系と、コストを最適化する方法について解説します。
BigQueryの料金体系
BigQueryの料金は、「コンピューティング料金」と「ストレージ料金」2つの要素で構成されています。
- コンピューティング料金:
SQLクエリ、ユーザー定義関数、スクリプト、特定のデータ操作言語(DML)とデータ定義言語(DDL)ステートメントなどのクエリの処理にかかる費用です。たとえば、BigQueryをデータソースとしたLooker Studioダッシュボードを操作する際に発生するクエリ費用は、こちらのコンピューティング料金に該当します。 - ストレージ料金:
BigQueryに読み込むデータの保存にかかる費用です。たとえば、GA4データをBigQueryに自動エクスポートしている場合、そのGA4テーブルを保存しておくための料金はこちらのストレージ料金に該当します。
コンピューティング料金とストレージ料金それぞれの費用は都度アップデートがあるため、詳しくはGoogle公式ドキュメントをご覧ください。
最適化1. 集計済みテーブルの作成
Looker StudioやTableauなどのBIツールからBigQueryに直接接続すると、ダッシュボードを操作するたびにクエリが発行されます。発行されるクエリの容量を抑えることにより、コンピューティング料金を最適化できます。その方法のひとつは、BigQueryで集計済みのテーブルを作成することです。
未集計のテーブルは容量が大きくなりがちで、BIツールからクエリを発行する際に読み込むデータが大きくなってしまいます。そこで集計済みのテーブルを作成しておくと、テーブルサイズが小さくなり、BIツールからクエリを発行する際の読込データも小さくなります。
最適化2. パーティショニングとクラスタリング
BigQueryでテーブル作成する際に「パーティショニング」と「クラスタリング」を設定すると、テーブルデータを抽出する際のクエリ容量を最適化できます。
▼パーティショニングとは
パーティショニングとは、BigQueryのテーブルをパーティションと呼ばれるセグメントで、内部的に分割することを意味します。パーティショニングでテーブルを分割するためには、テーブル作成時に分割の基準とする列をひとつ指定します。
WHERE句でパーティショニングに設定した列を指定すると、該当のパーティションのみを参照することができるため、クエリによるデータ読取容量を削減できます。
▼クラスタリングとは
クラスタリングとは、BigQueryのテーブルを内部的に並べ替え(ソート)することを意味します。クラスタリングをテーブルに適用するには、テーブル作成時に、並べ替えの基準とする列を指定します(最大4つ)。
WHERE句やGROUP BY句でクラスタリングに設定した列を指定すると、並び替えされたデータを参照するため、余計なデータの読み込みがスキップされ、クエリの高速化やデータ読取容量を削減できます。
パーティショニングとクラスタリングについてはブログ記事「BigQueryのパーティショニングとクラスタリングによるクエリ容量最適化の効果を検証してみた」で詳しく解説しています。あわせてご覧ください。
BigQuery × BIツールによるダッシュボード構築の例
BigQueryをBIツールと連携する方法について、Looker Studioを例に解説します。
Looker StudioのBigQuery接続方法
手順1. コネクタ接続
Looker Studioの上部メニュータブから「データを追加」を押下します。
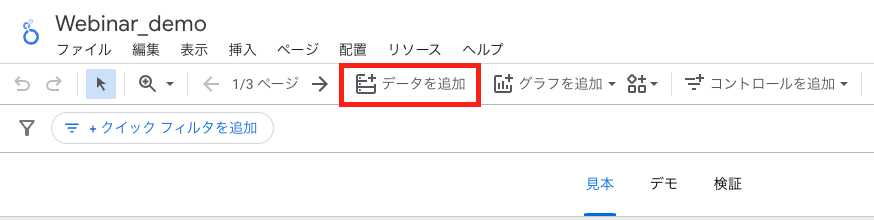
コネクタ一覧から「BigQuery」を選択します。
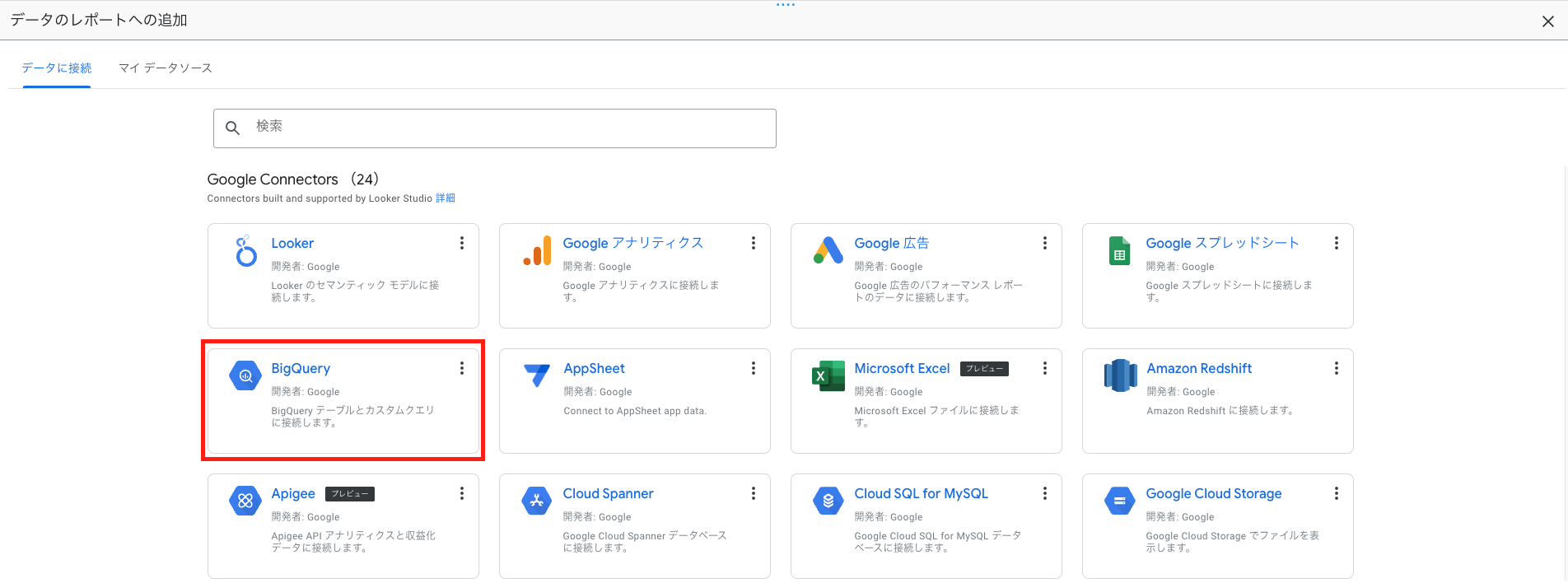
プロジェクト・データセット・テーブルを選択し、「追加」を押下します。
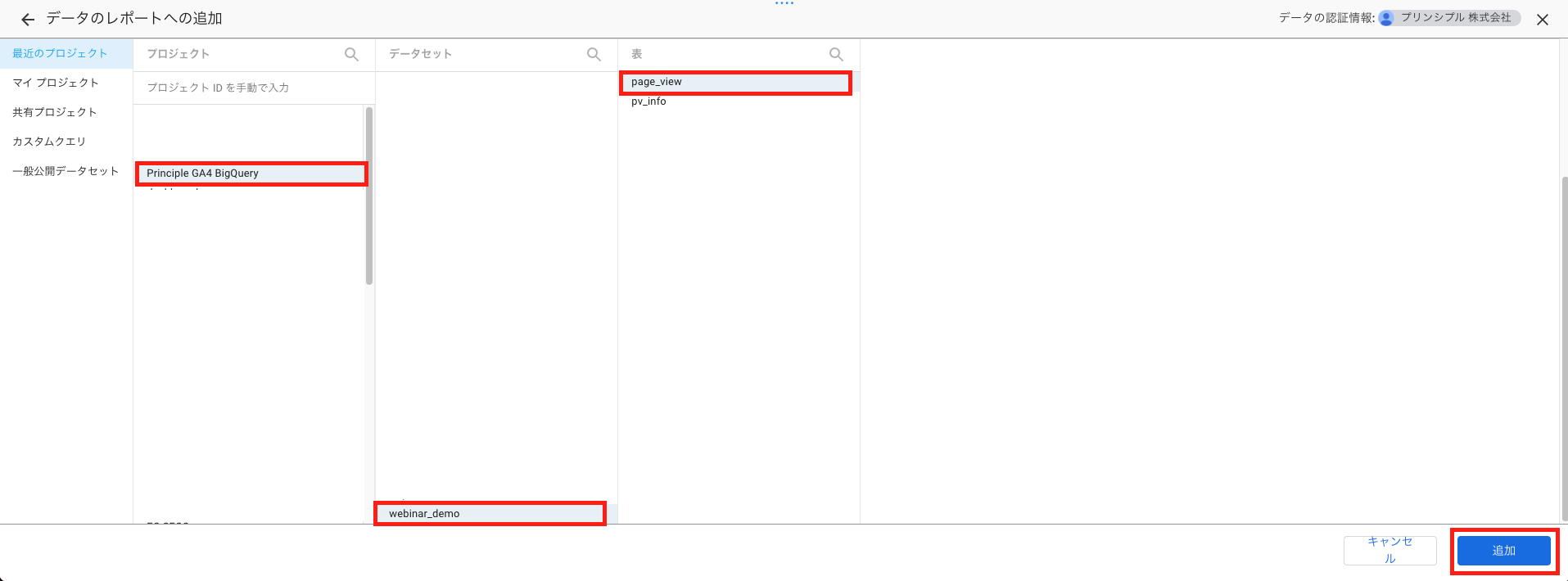
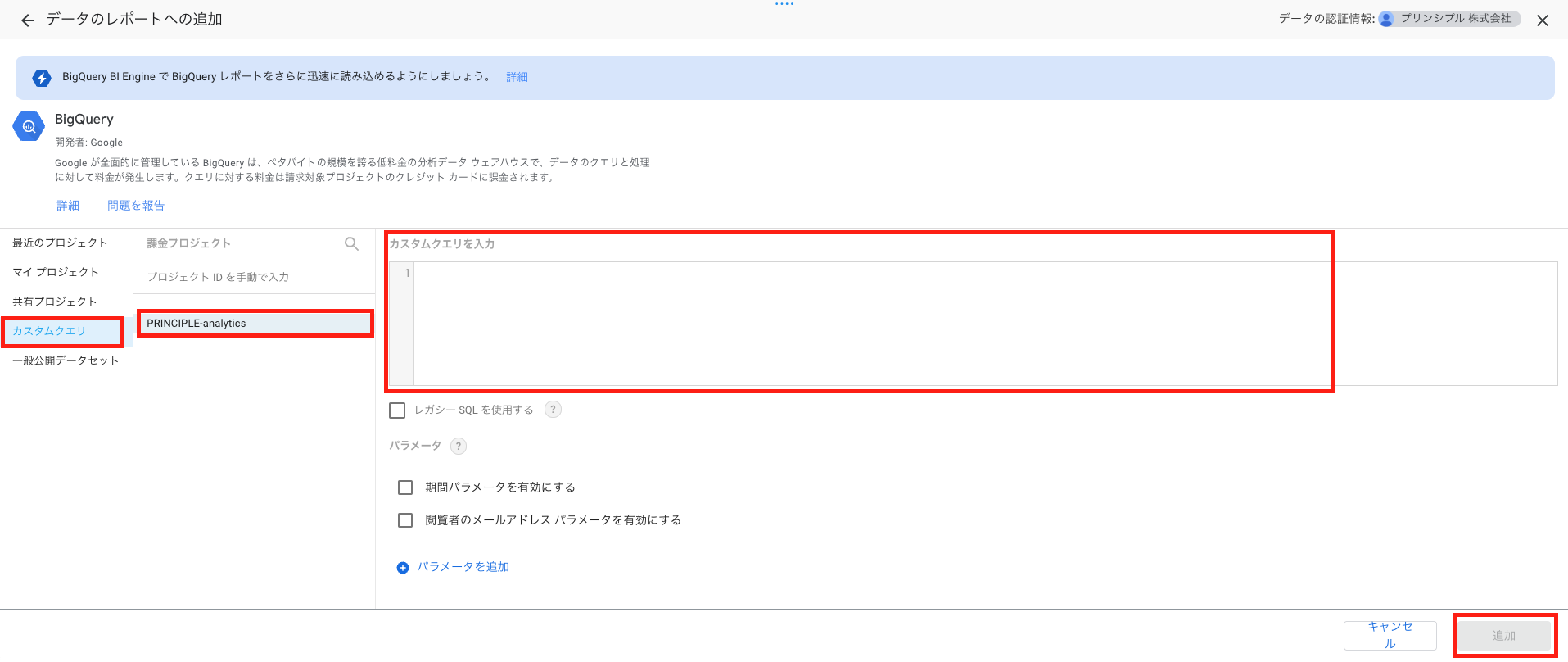
手順2. カスタムクエリ接続
Looker Studioの上部メニュータブから「データを追加」を押下します。
コネクタ一覧から「BigQuery」を選択します。
左側のメニューから「カスタムクエリ」を選択し、課金対象のプロジェクトを選択します。そして右側に表示されるボックスにSQLクエリを入力し、「追加」を押下します。
BigQuery × LookerStudioのダッシュボードサンプル
弊社が構築したダッシュボードの一部をご紹介します。
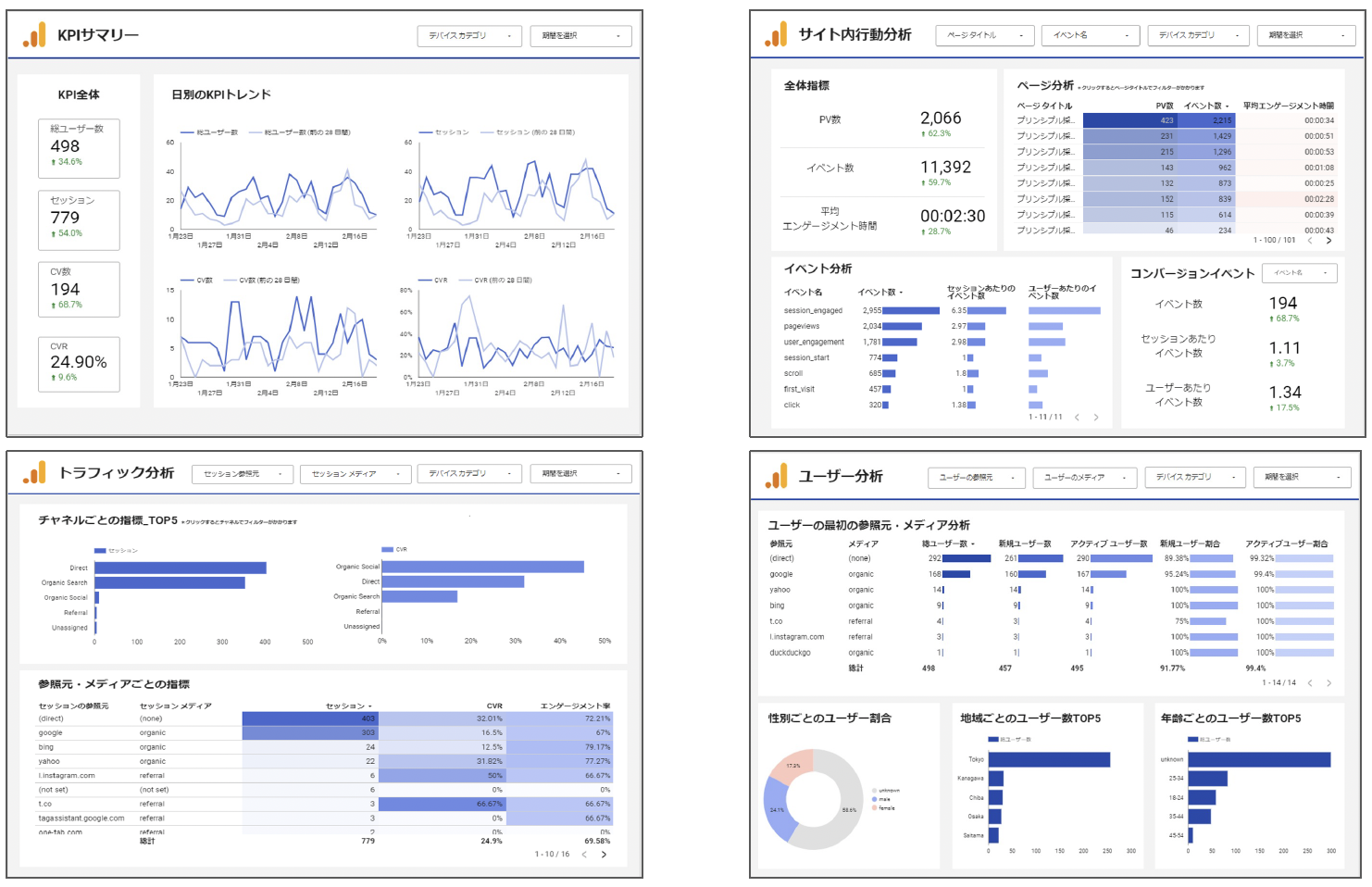
BigQuery活用事例
GA4のBigQueryエクスポートデータを活用して、ダッシュボード構築を行った事例を3つ紹介します。
事例①:GA4深堀り分析ダッシュボード
BigQueryを活用して、GA4データの深堀り分析ダッシュボードを構築した事例です。
BIツールでGA4データを可視化する際の懸念点として、セグメント機能が使用できないことや、データにサンプリングがかかってしまうことが挙げられます。BigQueryエクスポートデータを活用することで、サンプリングのかかっていない生データをSQLで加工し、セグメントを再現できます。
こちらの事例では、コンバージョンユーザーのリードタイムを可視化し、初回訪問からの経過日数や訪問回数をモニタリングできる環境を構築しました。
事例②:GA4×SFA統合分析ダッシュボード(1)
GA4とSFAのデータ統合ダッシュボードを構築した事例です。
オンライン・オフライン両方のユーザー行動を一気通貫で追跡することを目的に、GA4データとSFA(SFDC)データの統合ダッシュボードを構築しました。
これにより、Webで問い合わせをしたユーザーがその後の商談を経て成約まで至ったのか否か、そのユーザーはどのような特性のユーザーなのか、初回接触チャネルは何だったのかなどのフルファネル分析を実現しました。
詳しくは下記ページをご覧ください。
事例③:GA4×SFA統合分析ダッシュボード(2)
GA4とSFAのデータ統合ダッシュボードを構築した2つ目の事例です。
BtoCのリード獲得がオンラインで発生するWebサイトで、(1)の事例と同様にデータを統合しリード獲得後の商談獲得率、受注率などを一気通貫で追えるダッシュボードを構築しました。
Webサイトでのフォーム入力完了時に、GA4クライアントIDをGA4とSFAツールの顧客情報の両方に入るように設定し、クライアントIDを統合キーとすることで上記分析を実現しました。
また、本ダッシュボードはTableauにて構築しており、Looker Studioでは難易度の高いグラフなど高度な表現を実装しております。TableauとBigQueryの連携方法などは別途ご紹介いたします。
最後に
この記事では、GA4データをBigQueryに連携する方法から連携後の活用方法、ダッシュボードによるモニタリングまで、具体的な事例を交え解説しました。
GA4とBigQueryを連携させることで、多種多様な分析、長期間のデータ保持などさまざまなことが実現できます。弊社では連携支援から分析、他データとの統合支援まで一気通貫で支援が可能ですので、お気軽にお問い合わせください。








